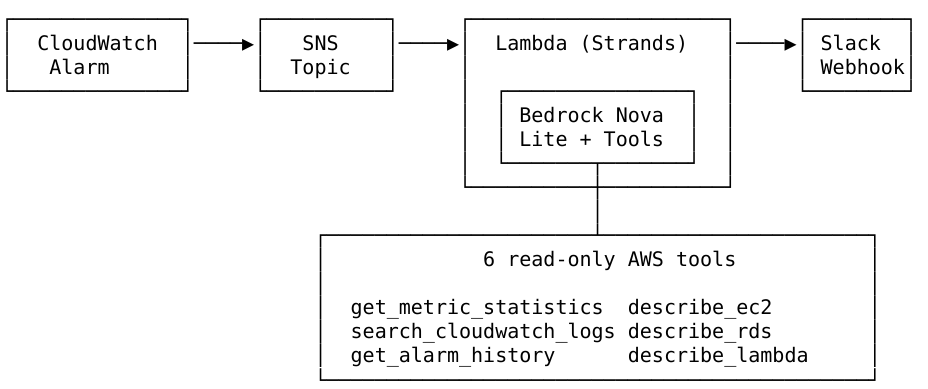
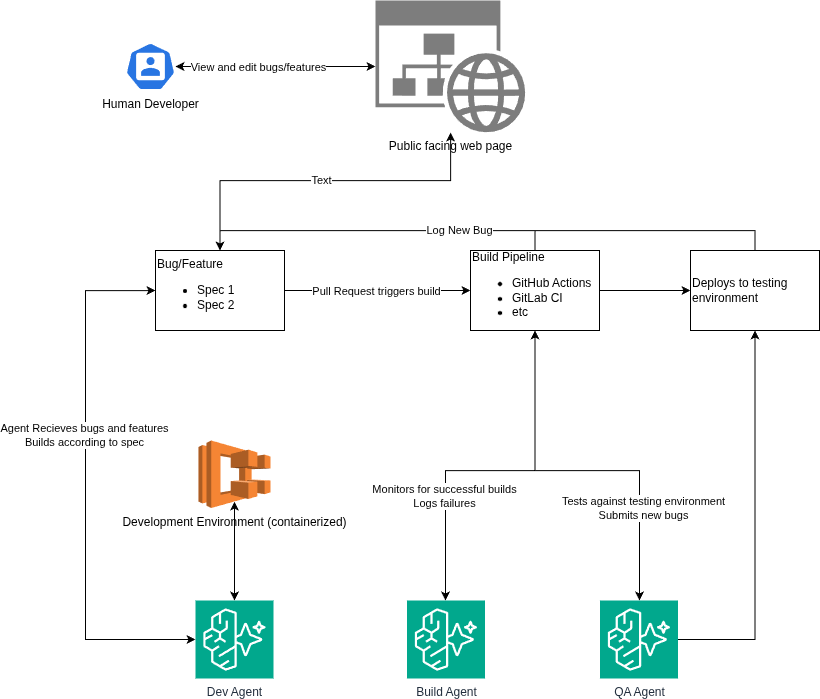
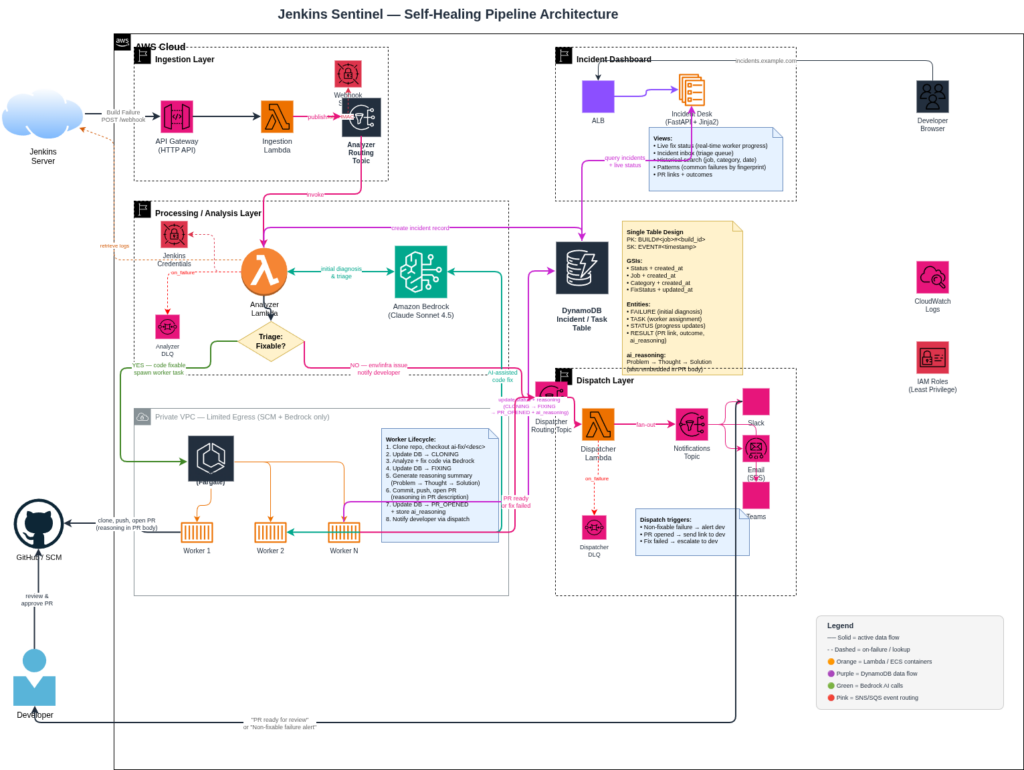
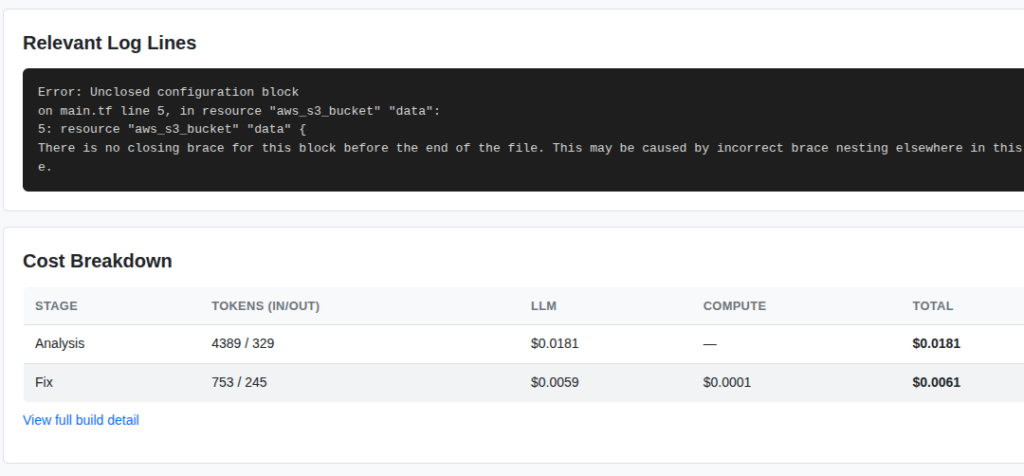
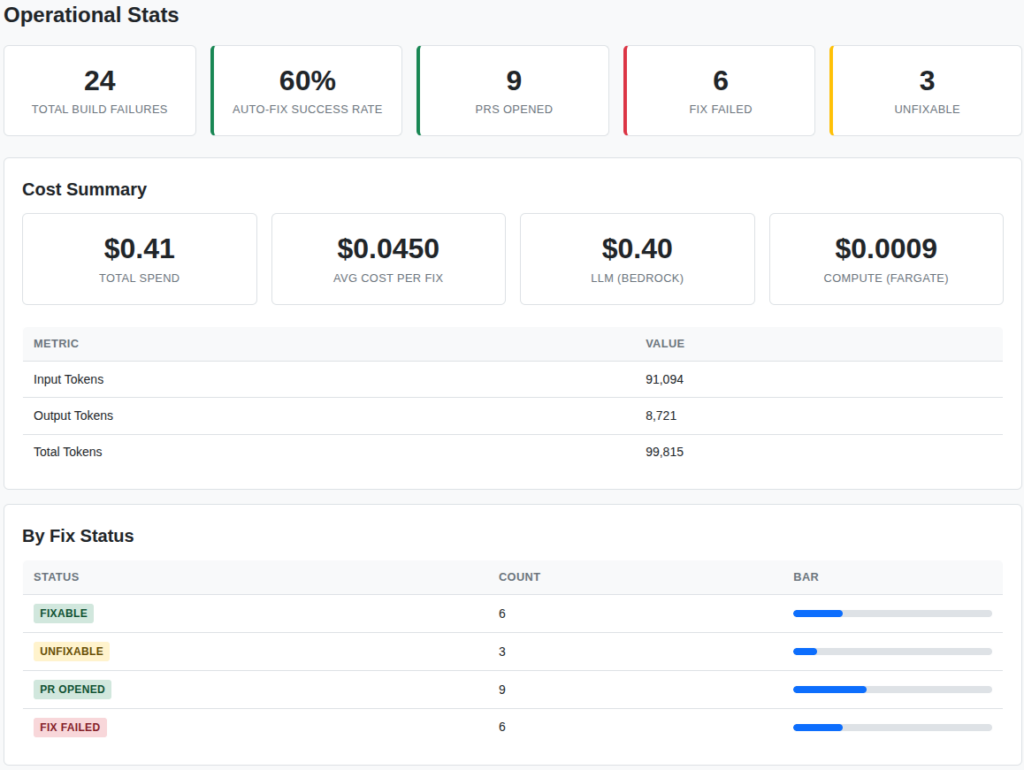
First off, I want to say I love Amazon Web Services, Kiro, and any effort that makes migrations from legacy to modern tech stacks. But, I also like the counter argument.
AWS launched AWS Transform as “a collaborative enterprise IT transformation workbench powered by expert agents.” It promises to modernize your .NET apps 5x faster, shrink mainframe projects from “years to months,” and automate VMware migrations end to end. The marketing page claims 4.5 billion lines of code analyzed and 1.69 million hours of manual effort saved in the last twelve months.
I’ve read the pitch. I’ve watched a couple of demos. I think most teams considering it should walk away, and I want to explain why —
and what to do instead.
What AWS Transform actual is
Strip the agentic-AI gloss off and Transform is three things bundled together:
- A discovery and assessment layer that scans your existing estate (codebases, VMs, dependencies).
- A set of pre-built “agents” that perform specific transformations: .NET Framework → .NET on Linux, COBOL → Java, VMware →
EC2, Java 8 → Java 21, and so on. - A workbench (web console plus Kiro IDE integration) where humans review and approve agent output.
It’s a continuation of a lineage: Migration Hub, MGN, App2Container, the old Microsoft Workloads tooling, the original CodeWhisperer transformation features. AWS keeps reshuffling these into new umbrella brands. Transform is the 2026 wrapper.
That history matters, because it tells you something about the half-life of the product you’re betting on.
My core objection: the output is shaped like AWS
When you let an agent translate a COBOL batch job into Java, or a .NET Framework service into .NET on Linux, you don’t just get “modern code.” You get code that looks the way AWS’s agent decided modern code should look. The data access patterns it picks, the logging conventions, the way it splits modules, the runtime targets it assumes — all of that is now baked into your codebase, and none of it was a decision your team made.
This is fine if you’re a hands-off shop that’s going to run whatever comes out the other end. It’s a disaster if you intend to own and evolve the system afterward. You will spend the next three years asking “why is it like this?” and the answer will be “because an agent decided in May 2026.”
There’s a deeper version of this problem with mainframe and VMware work. The agent doesn’t just translate code — it picks the AWS-native destination. Step Functions instead of your existing scheduler. DynamoDB instead of “let’s think about whether this data actually fits a KV store.” Network conversion that assumes you want VPC-native everything. These are not neutral technical choices; they are commercial decisions made on AWS’s behalf, inside your repo.
The metrics are a vendor-pitch, not a forecast
“5x faster.” “70% lower operating costs.” “Years to months.”
Every modernization vendor has said versions of these numbers for twenty years. They are real for the case study they came from. They are almost never what you will personally experience, because:
- The 70% cost reduction usually compares licensed Windows Server + SQL Server Standard on owned hardware against Linux +
an open-source database on Graviton. Most of the savings come from switching the license model, not from anything
Transform does. You can capture that yourself. - The “5x faster” number is measured against a baseline of “team that has never done this before, doing it manually.” If your
team has done a .NET migration once, your real multiplier is closer to 1.5x. - The mainframe-to-Java case studies almost always involve workloads that were already partially decomposed. The genuinely
tangled mainframes the ones where modernization is actually hard are not the ones that ship as case studies.
If a vendor’s headline metric needs four asterisks to be accurate, it isn’t really a metric.
Modernization that skips understanding is just translation
The thing I dislike most about Transform, and about agentic modernization in general, is that it lets you finish a project without anyone on your team understanding what they now own.
When a senior engineer spends six months untangling a COBOL system to port it, the porting is half the value. The other half is that, at the end, someone in the building understands the system. They know where the landmines are. They can answer questions in incident review. They can tell product what’s safe to change.
If an agent does the port, you get code on the other side and an organization that is no smarter than it was before. Worse: you now
have a Java codebase that nobody wrote and nobody fully grasps, sitting on top of business logic nobody re-derived. The first production incident will be ugly.
This is the same complaint people have about outsourced rewrites, and it applies cleanly to agent-driven ones.
The Kiro and tooling lock-in
Transform leans on Kiro, AWS’s IDE, with “pre-built playbooks.” Adopting Transform meaningfully means asking your engineers to learn Kiro, to work inside AWS’s review workflow, and to accept handoffs in a format that’s optimized for AWS’s agents to re-enter later.
That’s a real switching cost. Two years from now, when AWS rebrands Transform into whatever comes next, those playbooks and that workflow knowledge depreciate fast.
What to do instead
I’m not arguing for “do nothing” or “stay on the mainframe forever.” Modernization is often the right call. But the right shape is almost always:
- Do the assessment yourself, or with a consultancy you’d hire anyway. The discovery piece of Transform is the least controversial part — but it’s also the part you most want to own. Knowing your own estate is a permanent capability. Renting it from an agent is not.
- Use general-purpose coding agents under human direction, not vertical modernization agents. Claude Code, Cursor, Copilot in agent mode these are genuinely useful for the grunt work of a migration (rewriting a thousand similar files, fixing a known refactor pattern, translating tests). The difference is that your engineer is driving, deciding the target architecture, and reading the output. The agent is a force multiplier, not a contractor.
- Small wins, not big-bang. Pick the highest-pain module. Modernize it. Run it alongside the old system. Cut over. Repeat. This is slower on paper than “let the agent do it all,” but it produces a team that understands the new system at each step. And you can stop whenever the remaining legacy stops costing you money — which, for a lot of mainframe workloads, is the honest answer.
- Separate the license/runtime change from the architecture change. If most of your savings come from leaving Windows + SQL Server, do that migration as its own project. Don’t let it get bundled with a re-architecture, because the re-architecture is where the risk lives and you want it isolated.
- Be honest about workloads that shouldn’t move. Some legacy systems are stable, cheap to run, and changed once a quarter. Modernizing them is a status project, not a value project. Transform’s marketing will never tell you this; a good architect will.
TLDR:
AWS Transform is well-engineered. The agents work. The demos are real. None of that is the question.
The question is whether you want to end a multi-year modernization with a codebase shaped by AWS’s opinions, a team that didn’t learn the system, and a tooling dependency on a product line AWS will rename in two years.
For most teams I’ve worked with, the answer is no. Use agents — yours, under your control — to make your own engineers faster. Keep the architectural decisions in the building. Skip the workbench
Questions? Let me know.