Your cart is currently empty!
Category: Technology
Automating Proper Terraform Formatting using Git Pre-Hooks
I’ve noticed lately that a lot of Terraform is formatted differently. Some developers utilize two indents, others one indent. As long as the Terraform as functional most people overlook the formatting of their infrastructure as code files.
Personally I don’t think we should ever push messy code into our repositories. How could we solve this problem? Well, Terraform has a built in formatter theterraform fmtcommand will automatically format your code.#!/usr/bin/env bash # Initialize variables EXIT_CODE=0 AFFECTED_FILES=() # Detect OS for cross-platform compatibility OS=$(uname -s) IS_WINDOWS=false if [[ "$OS" == MINGW* ]] || [[ "$OS" == CYGWIN* ]] || [[ "$OS" == MSYS* ]]; then IS_WINDOWS=true fi # Find all .tf files - cross-platform compatible method if [ "$IS_WINDOWS" = true ]; then # For Windows using Git Bash TF_FILES=$(find . -type f -name "*.tf" -not -path "*/\\.*" | sed 's/\\/\//g') else # For Linux/Mac TF_FILES=$(find . -type f -name "*.tf" -not -path "*/\.*") fi # Check each file individually for better reporting for file in $TF_FILES; do # Get the directory of the file dir=$(dirname "$file") filename=$(basename "$file") # Run terraform fmt check on the specific file - handle both OS formats terraform -chdir="$dir" fmt -check "$filename" >/dev/null 2>&1 # If format check fails, record the file if [ $? -ne 0 ]; then AFFECTED_FILES+=("$file") EXIT_CODE=1 fi done # If any files need formatting, list them and exit with error if [ $EXIT_CODE -ne 0 ]; then echo "Error: The following Terraform files need formatting:" for file in "${AFFECTED_FILES[@]}"; do echo " - $file" done echo "" echo "Please run the following command to format these files:" echo "terraform fmt -recursive" exit 1 fi echo "All Terraform files are properly formatted" exit 0Put this code inside your “.git/hooks/” directory so that it automatically runs when someone does a push. If there is badly formatted Terraform you should see something like:
Running Terraform format check... Error: The following Terraform files need formatting: - ./main.tf Please run the following command to format these files: terraform fmt -recursive error: failed to push some refs to 'github.com:avansledright/terraform-fmt-pre-hook.git'After running the <code>terraform fmt -recursive</code> it should push successfully!
If this was helpful to your or your team please share it across your social media!
Building a Python Script to Export WordPress Posts: A Step-by-Step Database to CSV Guide
Today, I want to share a Python script I’ve been using to extract blog posts from WordPress databases. Whether you’re planning to migrate your content, create backups, or analyze your blog posts, this tool makes it straightforward to pull your content into a CSV file.
I originally created this script when I needed to analyze my blog’s content patterns, but it’s proven useful for various other purposes. Let’s dive into how you can use it yourself.
Prerequisites
Before we start, you’ll need a few things set up on your system:
- Python 3.x installed on your machine
- Access to your WordPress database credentials
- Basic familiarity with running Python scripts
Setting Up Your Environment
First, you’ll need to install the required Python packages. Open your terminal and run:
pip install mysql-connector-python pandas python-dotenvNext, create a file named
.envin your project directory. This will store your database credentials securely:DB_HOST=your_database_host DB_USERNAME=your_database_username DB_PASS=your_database_password DB_NAME=your_database_name DB_PREFIX=wp # Usually 'wp' unless you changed it during installationThe Script in Action
The script is pretty straightforward – it connects to your WordPress database, fetches all published posts, and saves them to a CSV file. Here’s what happens under the hood:
- Loads environment variables from your .env file
- Establishes a secure connection to your WordPress database
- Executes a SQL query to fetch all published posts
- Converts the results to a pandas DataFrame
- Saves everything to a CSV file named ‘wordpress_blog_posts.csv’
Running the script is as simple as:
python main.pySecurity Considerations
A quick but important note about security: never commit your .env file to version control. I’ve made this mistake before, and trust me, you don’t want your database credentials floating around in your Git history. Add .env to your .gitignore file right away.
Potential Use Cases
I wrote this script to feed my posts to AI to help with SEO optimization and also help with writing content for my other businesses. Here are some other ways I’ve found this script useful:
- Creating offline backups of blog content
- Analyzing post patterns and content strategy
- Preparing content for migration to other platforms
- Generating content reports
Room for Improvement
The script is intentionally simple, but there’s plenty of room for enhancement. You might want to add:
- Support for extracting post meta data
- Category and tag information
- Featured image URLs
- Comment data
Wrapping Up
This tool has saved me countless hours of manual work, and I hope it can do the same for you. Feel free to grab the code from my GitHub repository and adapt it to your needs. If you run into any issues or have ideas for improvements, drop a comment below.
Happy coding!
Get the code on GitHub
2024 Year in Review: A Journey Through Code and Creation
As another year wraps up, I wanted to take a moment to look back at what I’ve shared and built throughout 2024. While I might not have posted as frequently as in some previous years (like 2020’s 15 posts!), each post this year represents a significant technical exploration or project that I’m proud to have shared.
The Numbers
This year, I published 9 posts, maintaining a steady rhythm of about one post per month. April was my most productive month with 2 posts, and I managed to keep the blog active across eight different months of the year. Looking at the topics, I’ve written quite a bit about Python, Lambda functions, and building various tools and automation solutions. Security and Discord-related projects also featured prominently in my technical adventures.
Highlights and Major Projects
Looking back at my posts, a few major themes emerged:
- File Processing and Automation: I spent considerable time working with file processing systems, creating efficient workflows and sharing my experiences with different approaches to handling data at scale.
- Python Development: From Lambda functions to local tooling, Python remained a core focus of my technical work this year. I’ve shared both successes and challenges, including that Thanksgiving holiday project that consumed way more time than expected (but was totally worth it!).
- Security and Best Practices: Throughout the year, I maintained a strong focus on security considerations in development, sharing insights and implementations that prioritize robust security practices.
Community and Testing
One consistent theme in my posts has been the value of community feedback and testing. I’ve actively sought input on various projects, from interface design to data processing implementations. This collaborative approach has led to more robust solutions and better outcomes.
Looking Forward to 2025
As we head into 2025, I’m excited to increase my posting frequency while continuing to share technical insights, project experiences, and practical solutions to real-world development challenges. There are already several projects in the pipeline that I can’t wait to write about. I also hope to ride 6000 miles on my bike throughout Chicago this year.
For those interested my most popular Github repositories were:
- bedrock-poc-public
- count-s3-objects
- delete-lambda-versions
- dynamo-user-manager
- genai-photo-processor
- lex-bot-local-tester
- presigned-url-gateway
- s3-object-re-encryption
Thank You
To everyone who’s read, commented, tested, or contributed to any of the projects I’ve written about this year – thank you. Your engagement and feedback have made these posts and projects better. While this year saw fewer posts than some previous years, each one represented a significant project or learning experience that I hope provided value to readers.
Here’s to another year of coding, learning, and sharing!
The Discord Bot Framework
I’m happy to announce the release of my Discord Bot Framework. A tool that I’ve spent a considerable amount of time working on to help people build and deploy Discord Bots quickly within AWS.

Let me first start off by saying I’ve never released a product. I’ve run a service business and I’m a consultant but I’ve never been a product developer. This release marks my first codebase that I’ve packaged and put together for developers and hobbyists to utilize.
So let’s talk about what this framework does. First and foremost it is not a fully working bot. There are pre-requisites that you must accomplish. The framework holds some example code for commands and message context responses which should be enough to get any Python developer started on building their bot. The framework also includes all of the required Terraform to deploy the bot within AWS.
When you launch the Terraform it will build a Docker image for you and deploy that image to ECR as well as launch the container within AWS Fargate. All of this lives behind a load balancer so that you can scale your bot’s resources as needed although I haven’t seen a Discord bot ever require that many resources!
I plan on supporting this project personally and providing support via email for the time being for anyone who purchases the framework.
Roadmap:
– GitHub Actions template for CI/CD
– More Bot example code for commands
– Bolt on packages for new functionalityI hope that this framework helps people get started on building bots for Discord. If you have any questions feel free to reach out to me at anytime!
Convert Spotify Links to Youtube Links
In a continuation of my Discord Bot feature deployment, I found a need to convert Spotify links to YouTube links. I use Youtube music for my music streaming needs and the rest of the Discord uses Spotify.
With the help of ChatGPT, I created a script that converts Spotify links to Youtube links! This utilizes both the Spotify API and Youtube APIs to grab track information and format search queries to return a relevant Youtube link.
The code consists of two primary functions which I have shared below. One to get the artist and track names and another to query YouTube. Combined, we can return a YouTube link to a multitude of applications.
def get_spotify_track_info(spotify_url): track_id = sp.track(spotify_url)['id'] track_info = sp.track(track_id) return { 'name': track_info['name'], 'artists': [artist['name'] for artist in track_info['artists']] } def search_youtube_video(track_info): search_query = f"{track_info['name']} {track_info['artists'][0]} official video" request = youtube.search().list(q=search_query, part='snippet', type='video', maxResults=1) response = request.execute() video_id = response['items'][0]['id']['videoId'] return f"https://www.youtube.com/watch?v={video_id}"I took this code and incorporated it into my Discord bot so that anytime a user posts a Spotify link it will automatically convert it to a Youtube link. Here is an example:

If you want to utilize this code check out the Github link below. As always, if you found this article helpful please share it across your social media.
Github – https://github.com/avansledright/spotify-to-youtube
SES Monitoring
I love AWS. But one thing they don’t do is build complete tools. SES is one of them. I recently started getting emails about high usage for one of the identities that I have set up for SES. I would assume that there was a way to track usage within CloudWatch but for the life of me I couldn’t find one. So I guess that means I need to build something.
The idea here is pretty simple, within SES identities you can set up a notification. So, I created an SNS topic and subscribed all delivery notifications to the topic. Then, subscribe a Lambda function to the topic. The lambda function acts as the processor for the records then formats them in a usable way and puts them into DynamoDB. I used the identity as the primary key. The result is a simple application architecture like the below image.
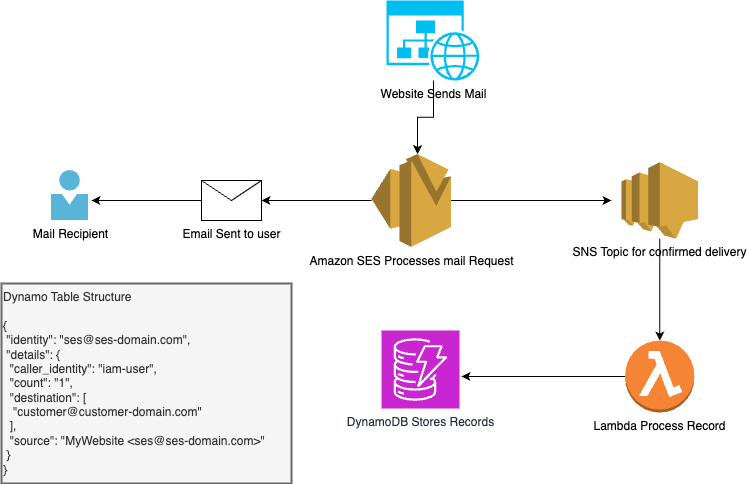
Every time an email is delivered the lambda function processes the event and checks the DynamoDB table to see if we have an existing record. If the identity is already present in the table it returns the “count” value so that we can increment the value. The “destination” value appends the destination of the email being sent. Below is a sample of the code I used to put the object into the DynamoDB Table.
def put_dynamo_object(dynamo_object): count = str(dynamo_get_item(dynamo_object)) if count == None or count == 0: count = str(1) else: count = int(count) + 1 # get email address from the long string source_string = dynamo_object['source'] email_match = match = re.search(r'[\w.+-]+@[\w-]+\.[\w.-]+', source_string) email = match.group(0) try: table.update_item( Key={ 'identity': email }, AttributeUpdates={ 'details': { 'Value': { 'caller_identity': dynamo_object['caller_identity'], 'source': dynamo_object['source'], 'destination': dynamo_object['destination'], 'count': str(count) } } } ) return True except ClientError as e: print("Failed to put record") print(e) return FalseIf you want to use this code feel free to reach out to me and I will share with you the Terraform to deploy the application and as always, reach out with questions or feedback!
Building a Discord Bot with Python and AWS
I’m a member of a lot of Discord servers. The one I participate in most is one with my brothers and our friends. In this server, we joke around a lot about people posting off-topic messages in the various text channels and we give them fake “warnings”. I decided to take this a step further and create a bot where we could track the warnings and then present them in a leaderboard.
The Discord bot API documentation is great and allowed me to quickly get a proof of concept up and running. I then relied on my Python, Terraform, and AWS skills to get the bot up and running quickly. Below is a simple architecture diagram that I started and will most likely be adding to as the members of the server request more features.

We have three current commands, !warning, !feature, !leaderboard. The !warning command takes input of a tagged user. It then uses the Boto3 library for Python and adds the attribute to the user in the table. Here is the code:
# Adds an attribute to a user def add_warning_to_user(username, attribute): client = boto3.resource("dynamodb", region_name="us-west-2", aws_access_key_id=os.getenv('AWS_KEY'), aws_secret_access_key=os.getenv('AWS_SECRET')) table = client.Table(table_name) print("adding", attribute, "to", str(username)) try: response = table.update_item( Key={'username': str(username)}, AttributeUpdates={attribute: { 'Value': str(dynamodb.get_warning_count_of_user(username, attribute) + 1) } } ) print(response) except ClientError as e: print("Failed to update count") print(e) return False return TrueI have another function within this code that will call out to the DynamoDB table and gets the user’s current value so that we can increment the count.
The !leaderboard command takes input of an “attribute” I built it this way so that we can have future attributes added to users without having to rebuild everything from scratch. To get the data I used the DynamoDB scan function to retrieve all of the data for all the users and then filter within the Python application on just the attribute that we are requesting the leaderboard for. I then have a function that formats the leaderboard into something that the bot can publish back to the server.
def create_table(data, attribute): if attribute == "warning_count": attribute = "Warnings" table = "" rows = [] rows.append("``` ") rows.append(f"{attribute}: Leaderboard") for key, value in data.items(): rows.append(f"{key}: {str(value)}") rows.append("``` ") for row in rows: table += " " + row + "\n " return tableThis code I want to revisit to make the formatting cleaner as the list gets longer. But for now it works as intended.
The last function I created so that the users could submit feature requests. The code is very simple and the command !feature takes the input of all text following the command and passes it to an SNS function I wrote which sends an email to me containing the user’s feature request. I have hopes that I can transition this to create some sort of Jira task or other workflow. Below is the bot’s code to handle this interaction:
@client.command(name="feature", help="sends a feature request") async def send_feature_request(ctx, *, args): print("THIS IS THE FEATURE REQUEST", args) if sns.send_message(args) == True: await ctx.send("Your request has been sent") else: await ctx.send("Failed to send your request. Plz try again later.")Right now the bot is running inside a Docker container within my homelab. I need to create better logging and implement some sort of logging server so that I can better handle errors as well as monitoring in case of any outages.
If you have questions about building Discord bots or AWS and its various components feel free to reach out to me at any time. This was a great project that I worked on over a few days and it was great to see it come together quickly!
Deleting many files from the Linux Command Line
I’ll admit that this post is more for me than any of my readers. I have this command that is buried in my notes and always takes me forever to dig back out. I figured I’d publish it on my blog so that I would maybe commit it to memory.
Let’s say that you have a directory with so many files that a simple “rm *” will always fail. I’ve encountered this with many WordPress logging plugins that don’t have log purging setup.
Enter this simple Linux command line command:
find <path> -type f -exec rm '{}' \;What this will do is find all the files in your path and delete them. You can modify this command with a bunch of other flags like:
find <path> -type f -mtime 30 -exec rm '{}' \;Which will only delete files that haven’t been modified in the last 30 days.
I’m sure there are many other flags and conditions you could check to create an even more fine-grained delete script but this has been useful for me!
If this helps you, please share this with your friends!
Subscribing All SES Identities to an SNS Topic
I recently ran across an issue where I was experiencing many bounced emails on my Amazon SES account. So much so that Amazon reached out and put me on a warning notice.
I realized that I had no logging in place to handle this. In order to create a logging mechanism I decided to send all “Bounce” notifications to a Slack channel so that I could better understand what was going on.
To accomplish this I first had to subscribe an SNS topic to a Slack channel. There are a multitude of ways that you can do this so I won’t go into detail here. If you have questions please reach out.
I wrote a simple function to loop through all of my identities in SES and then subscribe them to my SNS topic. Here is the code:
import boto3 ses = boto3.client('ses') response = ses.list_identities() for id in response['Identities']: update = ses.set_identity_notification_topic( Identity=id, NotificationType='Bounce', SnsTopic='<your SNS ARN here>' ) print(update)You can see this is a pretty straight forward loop that utilizes the Boto3 library in order to collect all of the identities.
Feel free to use this code however you want and if you have any questions reach out via email or social media!
Setting the Starting Directory for Windows Subsystem for Linux
I use Windows Subsystem for Linux almost every day. I run Ubuntu 20.04 for almost all of my development work. I recently re-installed Windows because I upgraded my PC after many years. One thing that has always bothered me is that when you launch WSL for the first time it doesn’t put you into your user’s home directory. But rather your Windows home directory. The fix for this is really quite simple.
First, navigate to the settings for Microsoft Terminal:

I use Visual Studio Code to do editing. Find the section that contains your WSL installation:

Just below the “source” line, add the following:
"startingDirectory": "//wsl$/Ubuntu-20.04/home/<user>",Replace “Ubuntu-20.04” with your distro name and “<user>” with your username.
Save and exit!