Taking a break from Fantasy Football today to talk about a quick weekend project I put together.
A friend of mine was chatting about how their AWS costs are getting out of control and they aren’t sure where to start when it comes to cleaning up the account. This prompted me with an idea to utilize AI to build an Agent that can interact with your AWS account to review resources, provide cost analysis and give you clear CLI commands or console instructions to help clean up the account.
In order to do this, I wanted to incur as little cost as possible. So, I built a Docker image in order to run it locally. First, there is a shell script that will build an IAM User in your account that provides read-only access to the account, Cost Explorer access and access to Bedrock (to communicate with an AI model).
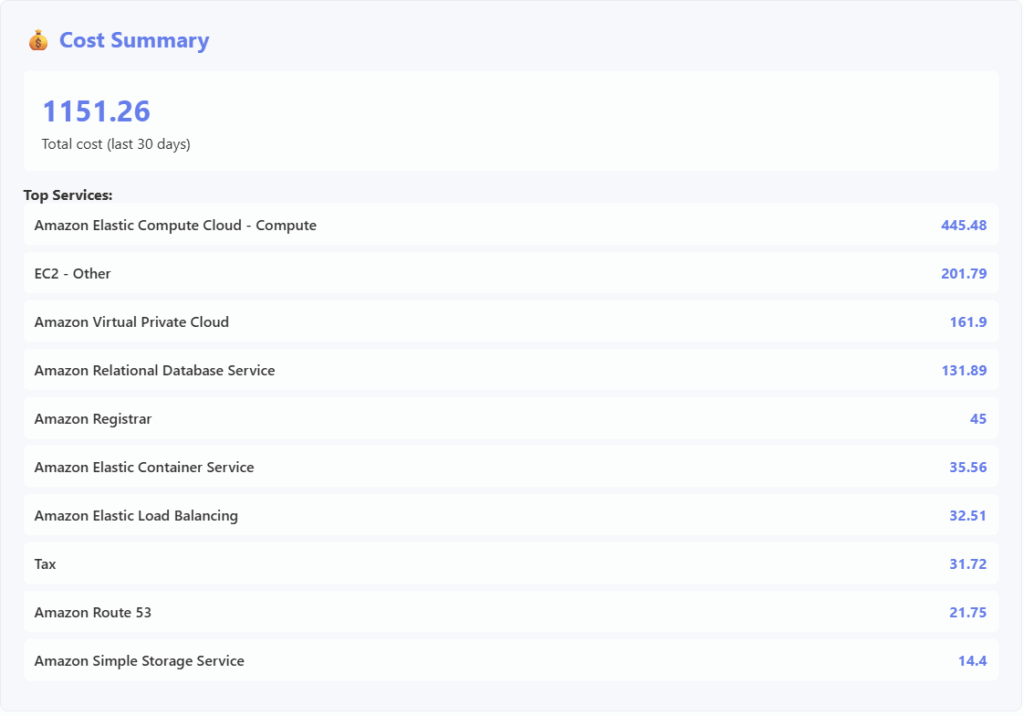
The Docker image runs and builds an Agent that interacts with whichever model you want to utilize. I picked Amazon’s Nova model just to keep the costs down. The container then presents a web interface where the account’s bill break down will be displayed:
It will also display some common costly resources and their counts:
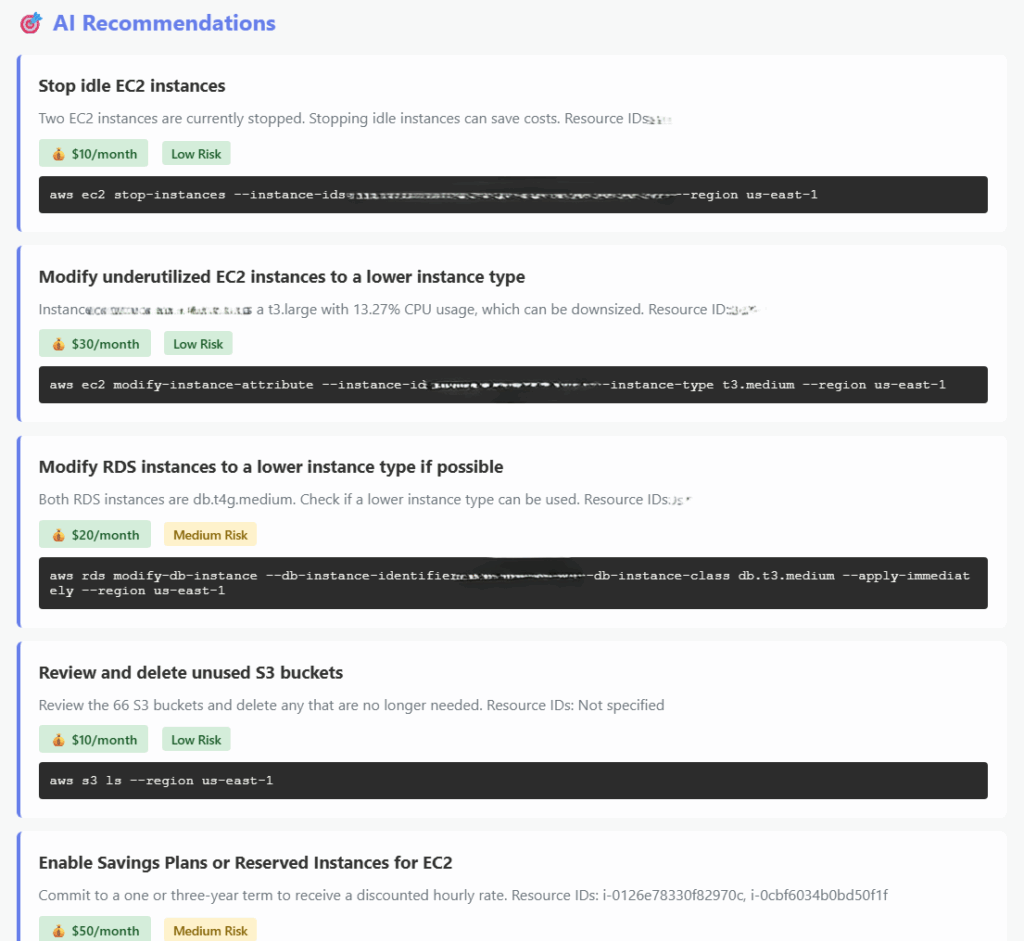
The next block is where things get very helpful. The AI will present to you suggestions as to how to save some money as well as some risk calculations. Because I ran this against my real account I had to blur out some information but you get the idea:
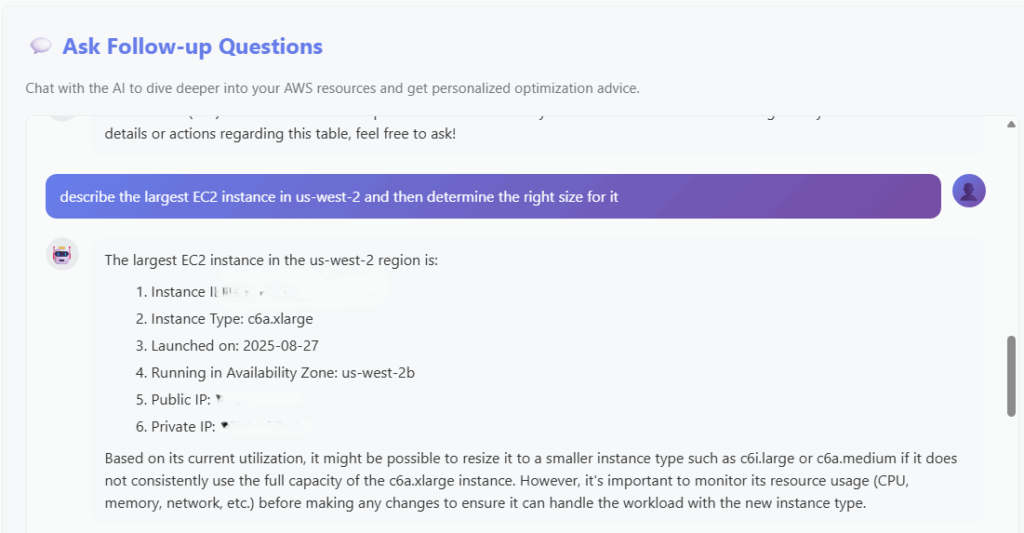
So, now you have some actionable activities to work through to help you save money on your AWS bill. But what if you have more questions? I also included a simple chat box to help you work with the bot to come up with other explanations or find other ways to save cost.
So I asked the AI to find the largest instance in my account and then determine the right size for it. Here is the response:
Why would this be important? Well, if you had the AI review all of the instances in your account you could identify EC2 instances that are oversized and have them be changed accordingly. After I implemented a few of the changes that the AI recommended (and verified they didn’t break anything), my account billing decreased by about $100.
If this is something you are interested in running on your own account feel free to reach out! I’d be happy to help you setup up the container on your machine and make suggestions as to how to save some money!
After a heartbreaking (lol) loss in week one, our agent is back with its picks for week two!
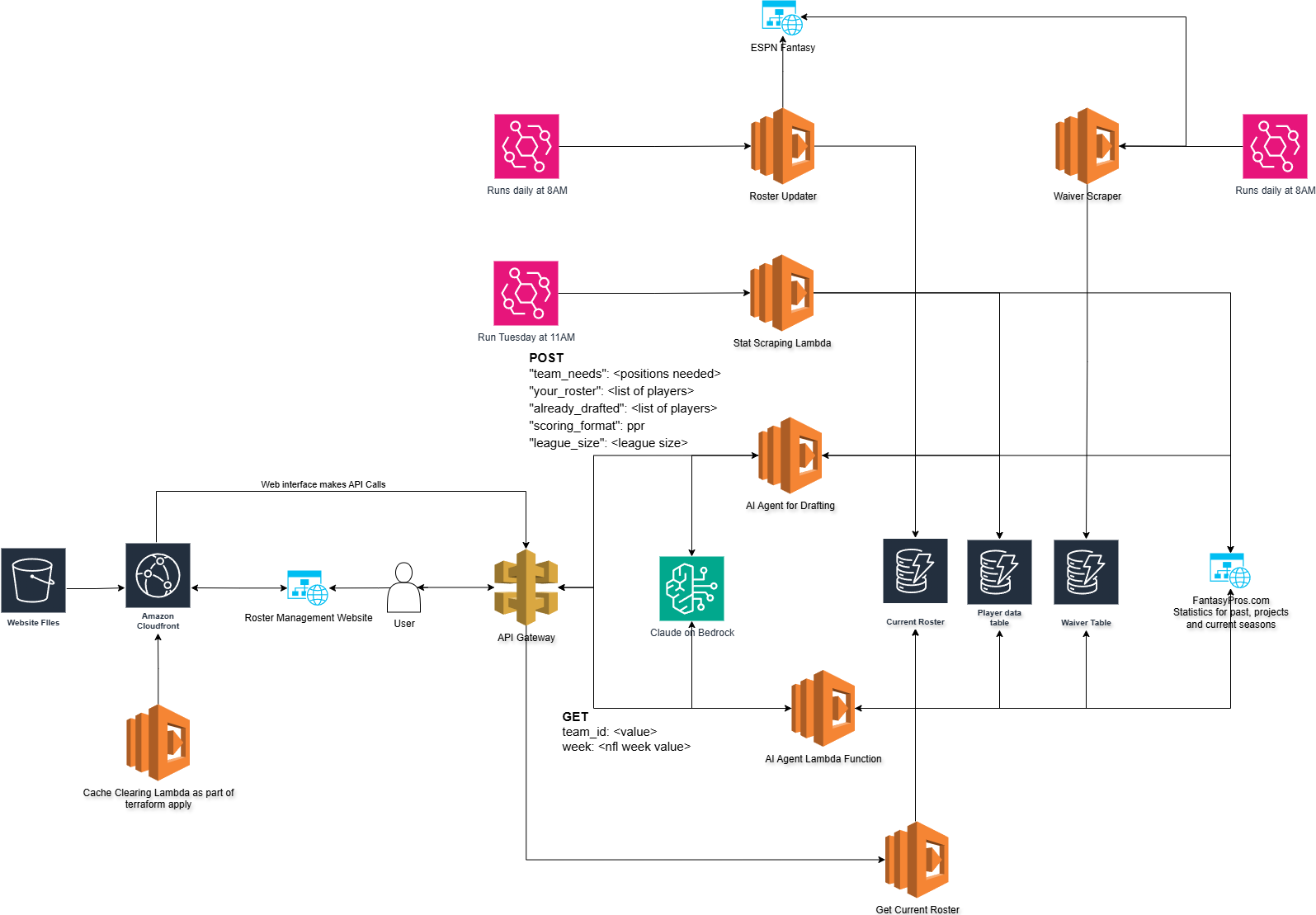
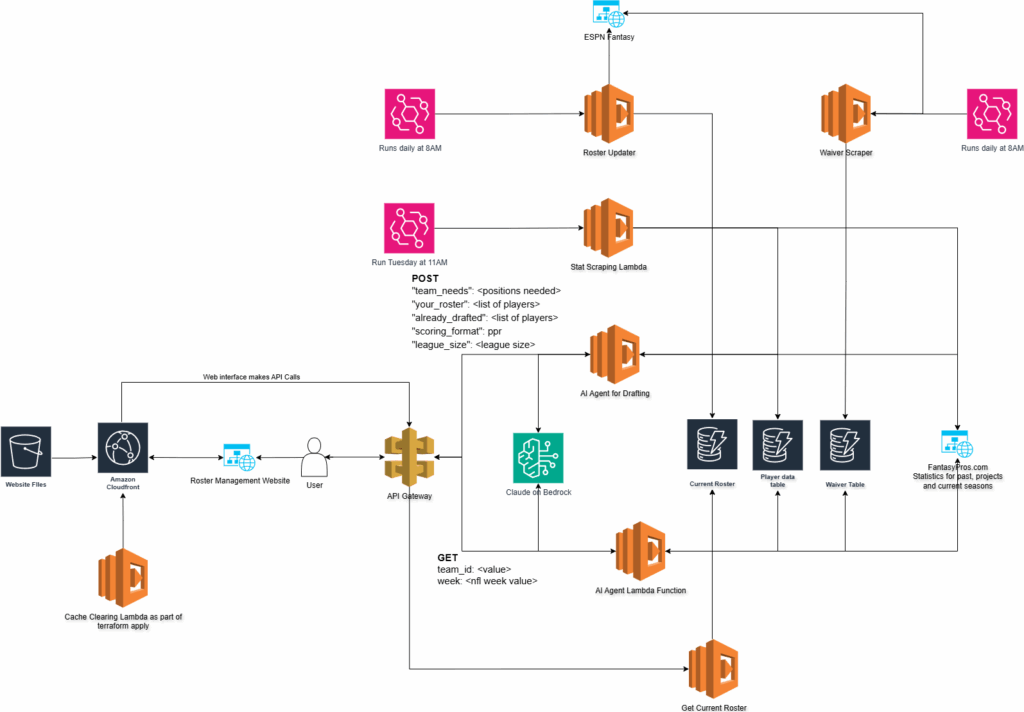
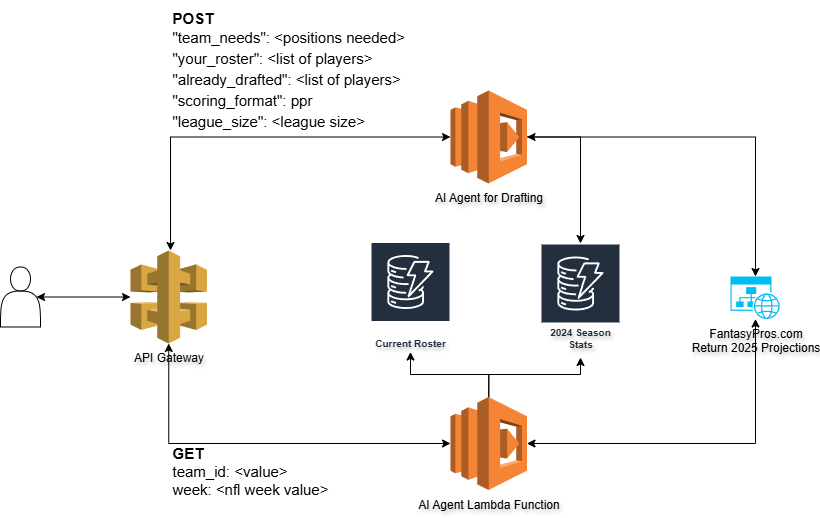
But, before we start talking about rosters and picks and how I think AI is going to lose week two, let’s talk about the overall architecture of the application.
Current Architecture diagram
You may notice that after my post on Tuesday I have substantially reduced the data storage. I’m now using three DynamoDB tables to handle everything.
Current Roster – This table is populated by an automated scraper that pulls the rosters for all the teams in the league.
Player Data Table – This table populates all the historical data from the draft as well as projected stats for the 2025 season. It also holds the actual points received after the week has completed.
Waiver Table – this is probably the most notable addition to the overall Agent. This table is populated by both ESPN and FantasyPros
The waiver wire functionality is a massive addition to the Agent. It now has the ability to know what players are available for me to add to the team. If we combine that with the player stats in the Player Data Table we can get a clear picture as to how the player MIGHT preform on a week to week basis.
The waiver table is populated by a lambda function that goes out and scrapes the ESPN Fantasy Platform. It is quite involved code as there is no API for ESPN. I’m still not sure why they don’t build one. It seems like an easy win for them especially as they get into more sports gambling. You can read the code here. This Lambda function runs on a CRON every day so that the Agent always has daily updated data.
The other major addition is a web interface. I realized that accessing this via a terminal is great but, it would be way more interesting to have something to look at. Especially if I am away from the computer.
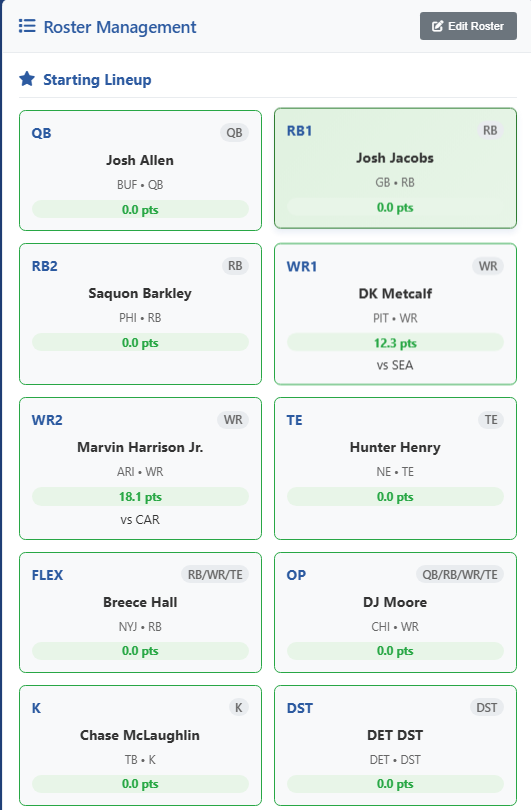
The web interface consists of a display of the roster:
Roster Screenshot
There are a couple things I need to fix. You’ll notice that a few players “have points” this is a problem with the data in the Player Data Table from when I was merging all the sources. Ideally, this will display the points the player has received for the week. Eventually I would like to add some live streaming of the point totals.
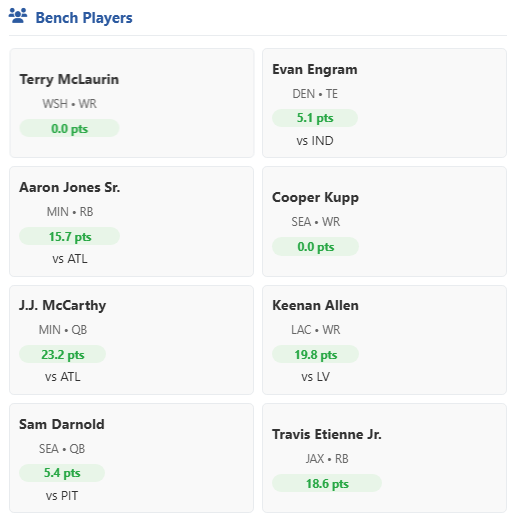
Bench Players
It also displays the bench (notice the same data glitch). On my list of things to do is to make these boxes drag and drop and auto update the roster table so that we can move players around. I also want to add their projections to each block so I can see the projected points per week for each player.
The BEST part (in my opinion) is the prediction functionality. There is a box that we can choose which week to get a prediction for and then it will return output from the agent.
So, let’s take a look at week two!
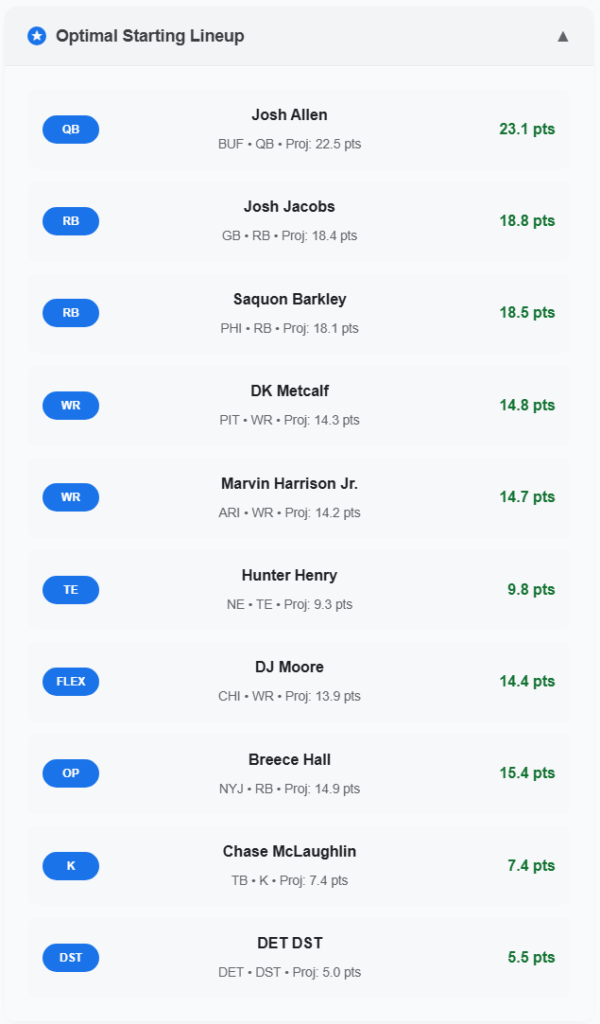
Optimal Week 2 Lineup
Here is a screenshot of the week two optimal lineup. This is the lineup I will be starting for week two unless one of my tight-ends becomes healthy. With George Kittle on injured reserve and Evan Engram also questionable, the AI suggested picking up Hunter Henry.
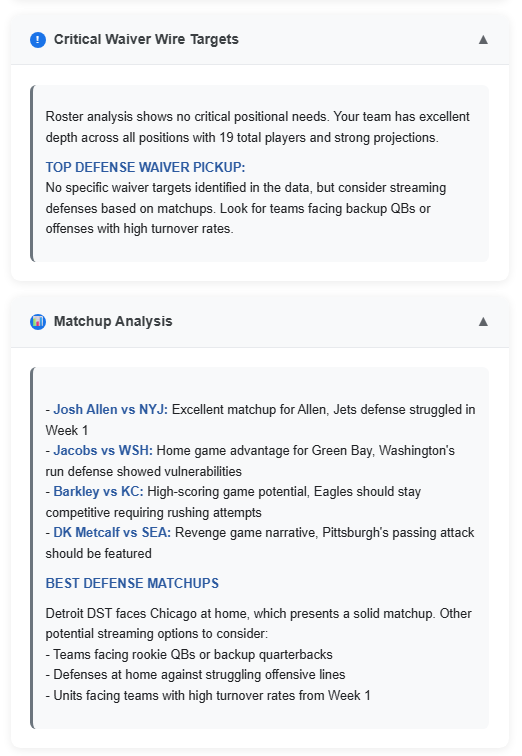
The Agent will also provide up with some waiver targets as well as matchup analysis
It will also output the full response for each week. Here is the full text of what the Agent has predicted for week two:
LINEUP OPTIMIZATION FOR WEEK 2
Starting Lineup Strategy: – Josh Allen (QB): Elite QB1 with 38.8 points in Week 1, facing NYJ defense that allowed significant passing yards. His 2024 average of 31.85 and strong 2025 projection make him a must-start. – Josh Jacobs (RB1): Top projected RB at 18.4 points, facing Washington at home. Green Bay’s new offensive system should benefit Jacobs significantly. – Saquon Barkley (RB2): Projected 18.1 points against Kansas City. His 2024 average of 15.93 and strong 2025 projection of 273.2 season points make him a core play. – DK Metcalf (WR1): Highest projected WR at 14.3 points. Pittsburgh vs Seattle should be a competitive game with passing volume. – Marvin Harrison Jr. (WR2): Rookie with 14.2 projection facing Carolina. His 154.5 season projection suggests breakout potential. – Hunter Henry (TE): Best available TE option at 9.3 projected points with Kittle on IR and Engram questionable. – DJ Moore (FLEX): Solid 13.9 projection against Detroit. Chicago’s passing game should see volume in what could be a high-scoring affair. – Breece Hall (OP): Critical OP selection at 14.9 projected points. Hall offers RB1 upside against Buffalo, and using an RB in the OP slot provides higher floor than WR options.
CRITICAL WAIVER WIRE TARGETS:
Roster analysis shows no critical positional needs. Your team has excellent depth across all positions with 19 total players and strong projections.
TOP DEFENSE WAIVER PICKUP: No specific waiver targets identified in the data, but consider streaming defenses based on matchups. Look for teams facing backup QBs or offenses with high turnover rates.
INJURY CONCERNS: – George Kittle: On Injury Reserve, unavailable for Week 2 – Evan Engram: Listed as Questionable, monitor his status throughout the week
MATCHUP ANALYSIS: – Josh Allen vs NYJ: Excellent matchup for Allen, Jets defense struggled in Week 1 – Jacobs vs WSH: Home game advantage for Green Bay, Washington’s run defense showed vulnerabilities – Barkley vs KC: High-scoring game potential, Eagles should stay competitive requiring rushing attempts – DK Metcalf vs SEA: Revenge game narrative, Pittsburgh’s passing attack should be featured
BEST DEFENSE MATCHUPS
Detroit DST faces Chicago at home, which presents a solid matchup. Other potential streaming options to consider: – Teams facing rookie QBs or backup quarterbacks – Defenses at home against struggling offensive lines – Units facing teams with high turnover rates from Week 1
WAIVER PRIORITY: 1. Streaming Defense: Look for defenses with favorable Week 3 matchups 2. Handcuff RBs: Target backup RBs for your elite runners (Jacobs, Barkley, Hall) 3. High-Upside WRs: Monitor snap counts and target shares from Week 2 for emerging receivers
Final Comments: Your roster is exceptionally deep and well-constructed. The OP position selection of Breece Hall provides excellent upside, as RBs typically offer higher floors than WRs in flex positions. Focus on matchup-based streaming for defense and monitor the waiver wire for breakout players rather than addressing positional needs. Your core lineup projects for strong Week 2 performance with multiple players having 15+ point upside.
What’s Next?
So we have a pretty solid week two prediction. Josh Allen and Saquon Barkley I have faith in. The rest of the team is hit or miss. Chicago faces Detroit at Ford Field (Go Lions!) and both teams lost week one. But Ben Johnson facing his old team for the first time has me nervous.
This brings up a few of my to-dos for the overall program.
Defensive matchups – I need to get data for the Defenses to find the best matchups week to week. Having a good defense play is an easy way to get an advantage every week.
Add authentication – I added a really simple authentication method to the code just for the time being. But, it would be nice to have a Single Sign On or something a little bit more secure.
Drag-n-drop interface – I need to add functionality to be able to modify the roster on the web interface. It would be nice if this could also update ESPN.
Slow Output – I’m always looking for ways to optimize the Agent’s output. Currently it takes about 45 seconds to a minute to return the output.
Thoughts? I hope this series is entertaining. If you have ideas for the Agent please comment below or shoot me a message somewhere!
The last you heard from me I was building a drafting agent for Fantasy Football. Well, the draft has finished and my roster is set. Behold, the Fantasy Football AI drafted team for my 8 team, PPR league.
STARTING LINEUP QB – Josh Allen (BUF) RB – Saquon Barkley (PHI) RB – Josh Jacobs (GB) WR – Terry McLaurin (WSH) WR – DJ Moore (CHI) TE – George Kittle (SF) FLEX – Breece Hall (NYJ) OP – Sam Darnold (SEA) D/ST – Lions (DET) K – Chase McLaughlin (TB) BENCH WR – DK Metcalf (PIT) WR – Marvin Harrison Jr. (ARI) TE – Evan Engram (DEN) RB – Aaron Jones Sr. (MIN) WR – Cooper Kupp (SEA) QB – J.J. McCarthy (MIN) WR – Keenan Allen (LAC) RB – Travis Etienne Jr. (JAX)
Now, I have also added another feature to the overall solution which is to include a week to week manager I’m calling the “coach”. I built a database that contains the 2024 statistics for each player and who they played against. I’m also scraping FantasyPros.com as well for future projections still.
I added a new Lambda function and API call to my architecture so that I can send a request to the AI Agent to build out my ideal weekly roster.
The roster I posted above is what I will be starting for week 1. The agent also provides some context as to why it selected each player.
🏈 Fantasy Lineup for Team 1, Week 1
==================================================
🏆 STARTING LINEUP:
QB: Josh Allen (BUF) 23.4 pts
RB: Saquon Barkley (PHI) 19.9 pts
RB: Josh Jacobs (GB) 15.5 pts
WR: Terry McLaurin (WAS) 11.1 pts
WR: DJ Moore (CHI) 12.5 pts
TE: George Kittle (SF) 10.6 pts
FLEX: Breece Hall (NYJ) 11.5 pts
OP: Sam Darnold (SEA) 18.6 pts
K: Chase McLaughlin (TB) 8.5 pts
DST: Lions (DET) 9.2 pts
💯 TOTAL PROJECTED: 145.4 points
📋 BENCH (Top 5):
WR: Keenan Allen 7.6 pts
WR: DK Metcalf 8.6 pts
WR: Marvin Harrison Jr. 9.5 pts
WR: Cooper Kupp 9.0 pts
RB: Aaron Jones Sr. 12.8 pts
💡 COACH ANALYSIS:
==================================================
Made one key adjustment to the computed lineup: replaced
Keenan Allen with DJ Moore at WR2. While Allen showed
decent recent form (9.325 avg last 4 games), DJ Moore is
the higher-drafted talent with WR1 upside who should be
prioritized in Week 1. Moore's lack of 2024 data likely
indicates injury, but his talent level and role in
Chicago's offense make him the better play. The rest of
the lineup is solid: Allen/Darnold QB combo maximizes
ceiling, Barkley/Jacobs/Hall provide strong RB production,
McLaurin offers consistency at WR1, and Kittle remains a
reliable TE1. Lions DST should perform well at home, and
McLaughlin provides steady kicking in Tampa Bay's offense.
==================================================
There are still some gaps I need to fill with the data set as D.J. Moore did play in 2024 so I’m likely missing some data sets. I also have plans to build a “general manager” who can scan available players and find maybe some hidden gems on a week to week basis.
Finally, command line tools are fun but, I think the solution needs a web interface so watch for updates on that. The coach will inevitably automated and send me a report on the weeks performance as well as suggestions for the following week.
If you like Fantasy Football and technology follow along to see how this team performs throughout the season!
Last year I attempted to program a Fantasy Football draft assistant which took live data from ESPN’s Fantasy Platform. Boy was that a mistake…
First of all, shame on ESPN for not having an API for their Fantasy sports applications. The reverse engineered methods were not fast enough nor were they reliable. So, this year I took a new approach to building out a system for getting draft pick recommendations for my team.
I also wanted to put to use the example architecture and code I wrote the other day for the Strands SDK to work so I utilized it to build an API which would utilize the AWS Bedrock platform to analyze data and and ultimately return the best possible picks.
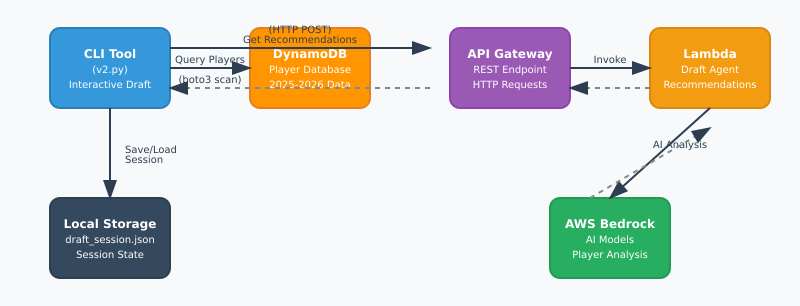
Here is a simple workflow of how the tool works:
I generated this with Claude AI. It is pretty OK.
The first problem I encountered was getting data. I needed two things: 1. Historical data for players 2. Projected fantasy data for the upcoming season
The historical data provides information about the players past season and the projections are for the upcoming season, obviously. The projections are useful because of any incoming rookies.
In the repository I link below I put a scripts to scrape FantasyPros for both the historical and projected data. It stores them in separate files in case you want to utilize them in a different way. There is also a script to combine them into one data source and ultimately load them into a DynamoDB table.
The most important piece of the puzzle was actually simulating the draft. I needed to create a program that would be able to track the other team’s draft picks as well as give me the suggestions and track my teams picks. This is the heart of the repository and I will be using it to get suggestions and track the draft for this coming season.
Through the application, when you issue the “next” command the application will send a request to the API with the current situation of the draft. The payload looks like this:
The “team_needs” key represents the current number of players remaining for each position. The “your_roster” position is all of the current players on my team. The other important key is “already_drafted”. This key sends all of the drafted players to the AI agent so it knows who NOT to recommend.
The application goes through all of the picks and you are able to manually enter each of the other teams picks until the draft is complete.
I’ll post an update after my draft on August 24th with the team I end up with! I still will probably lose in my league but this was fun to build. I hope to add in some sort of week-to-week management of my team as well as a trade analysis tool in the future. It would also be cool to add in some sort of analysis that could send updates to my Slack or Discord.
If you have other ideas message me on any platform you can find me on!
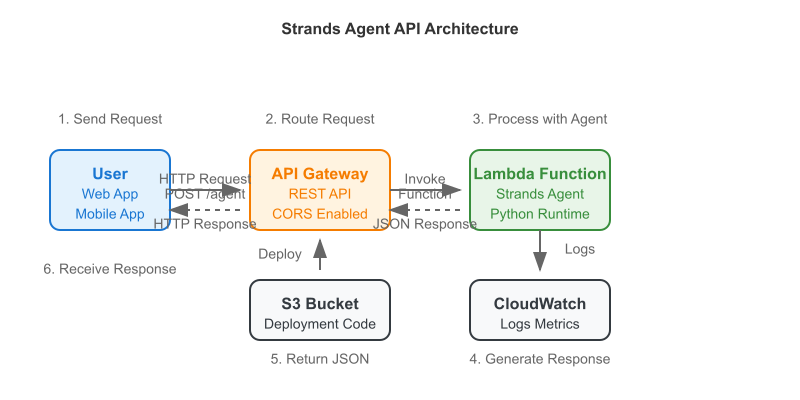
Recently I’ve been exploring the AI space a lot more as I’m sure a lot of you are doing as well. I’ve been looking at the Strands Agent SDK. I see this SDK as being very helpful in building out agents in the future (follow the blog to see what I come up with!).
One thing that is not included in the SDK is the ability to deploy with Terraform. The SDK includes examples of how to package and deploy with Amazon Web Services CDK so I adapted that to utilize Terraform.
I took my adaptation a step further and added an API Gateway layer so that you have the beginnings of a very simple AI agent deployed with the Strands SDK.
The code in the repository is fairly simple and includes everything you need to build an API Gateway, Lambda function, and some other useful resources just to help out.
The key to all of this is packaging the required dependencies inside of the Lambda Layer. Without this the function will not work.
File structure: terraform-strands-agent-api/ └── lambda_code/ │ ├── lambda_function.py # Your Strands agent logic │ └── requirements.txt # strands-agents + dependencies ├── api_gateway.tf # API Gateway configuration ├── iam.tf # IAM roles and policies ├── lambda.tf # Lambda function setup ├── locals.tf # Environment variables ├── logs.tf # CloudWatch logging ├── s3.tf # Deployment artifacts ├── variables.tf # Configurable inputs └── outputs.tf # API endpoints and resource IDs
You shouldn’t have to change much in any of these files until you want to fully start customizing the actual functionality of the agent.
To get started follow the instructions below!
git clone https://github.com/avansledright/terraform-strands-agent-api
cd terraform-strands-agent-api
# Configure your settings. Add other values as needed
echo 'aws_region = "us-west-2"' > terraform.tfvars
# Deploy everything
terraform init
terraform plan
terraform apply
If everything goes as planned you should see the output of a curl command which will give you the ability to test the demo code.
If you run into any issues feel free to let me know! I’d be happy to help you get this up and running.
I find myself utilizing the same architecture for deploying demo applications on the great Python library Flask. I’ve been using the same Terraform files over and over again to build out the infrastructure.
Last weekend I decided it was time to build a reusable framework for deploying these applications. So, I began building out the repository. The purpose of this repository is to give myself a jumping off point to quickly deploy applications for demonstrations or live environments.
Let’s take a look at the features:
Customizable Environments within Terraform for managing the infrastructure across your development and production environments
Modules for:
Application Load Balancer
Elastic Container registry
Elastic Container Service
VPC & Networking components
Dockerfile and Docker Compose file for launching and building the application
Demo code for the Flask application
Automated build and deploy for the container upon code changes
This module is built for any developer who wants to get started quickly and deploy applications fast. Using this framework will allow you to speed up your development time by being able to focus solely on the application rather than the infrastructure.
Upcoming features:
CI/CD features using either GitHub Actions or Amazon Web Services like CodePipeline and Codebuild
Custom Domain Name support for your application
If there are other features you would like to see me add shoot me a message anytime!
I have a PowerPoint party to go to soon. Yes you read that right. At this party everyone is required to present a short presentation about any topic they want. Last year I made a really cute presentation about a day in the life of my dog.
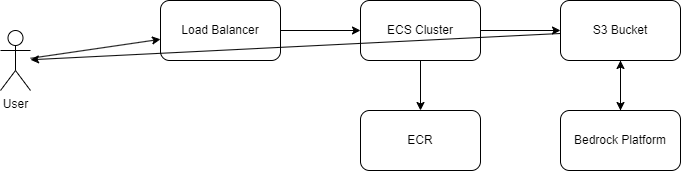
This year I have decided that I want to bore everyone to death and talk about technology, Python, Terraform and Artificial Intelligence. Specifically, I built an application that allows a user to upload an image and have it return to them a renamed file that is labeled based on the object or scene in the image.
The architecture is fairly simple. We have a user connecting to a load balancer which routes traffic to our containers. The containers connect Bedrock and S3 for image.
If you want to try it out the site is hosted at https://image-labeler.vansledright.com It will be up for some time, I haven’t decided how long I will host it for but at least through this weekend!
Here is the code that interacts with Bedrock and S3 to process the image:
def process_image():
if not request.is_json:
return jsonify({'error': 'Content-Type must be application/json'}), 400
data = request.json
file_key = data.get('fileKey')
if not file_key:
return jsonify({'error': 'fileKey is required'}), 400
try:
# Get the image from S3
response = s3.get_object(Bucket=app.config['S3_BUCKET_NAME'], Key=file_key)
image_data = response['Body'].read()
# Check if image is larger than 5MB
if len(image_data) > 5 * 1024 * 1024:
logger.info("File size to large. Compressing image")
image_data = compress_image(image_data)
# Convert image to base64
base64_image = base64.b64encode(image_data).decode('utf-8')
# Prepare prompt for Claude
prompt = """Please analyze the image and identify the main object or subject.
Respond with just the object name in lowercase, hyphenated format. For example: 'coca-cola-can' or 'golden-retriever'."""
# Call Bedrock with Claude
response = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": response['ContentType'],
"data": base64_image
}
}
]
}
]
})
)
response_body = json.loads(response['body'].read())
object_name = response_body['content'][0]['text'].strip()
logging.info(f"Object found is: {object_name}")
if not object_name:
return jsonify({'error': 'Could not identify object in image'}), 422
# Get file extension and create new filename
_, ext = os.path.splitext(unquote(file_key))
new_file_name = f"{object_name}{ext}"
new_file_key = f'processed/{new_file_name}'
# Copy object to new location
s3.copy_object(
Bucket=app.config['S3_BUCKET_NAME'],
CopySource={'Bucket': app.config['S3_BUCKET_NAME'], 'Key': file_key},
Key=new_file_key
)
# Generate download URL
download_url = s3.generate_presigned_url(
'get_object',
Params={
'Bucket': app.config['S3_BUCKET_NAME'],
'Key': new_file_key
},
ExpiresIn=3600
)
return jsonify({
'downloadUrl': download_url,
'newFileName': new_file_name
})
except json.JSONDecodeError as e:
logger.error(f"Error decoding Bedrock response: {str(e)}")
return jsonify({'error': 'Invalid response from AI service'}), 500
except Exception as e:
logger.error(f"Error processing image: {str(e)}")
return jsonify({'error': 'Error processing image'}), 500
If you think this project is interesting, feel free to share it with your friends or message me if you want all of the code!
I’m going to start this post of by saying that I need testers. People to test this process from an interface perspective as well as a data perspective. I’m limited on the amount of test data that I have to put through the process.
With that said, I spent my Thanksgiving Holiday writing code, building this project and putting in way more time that I thought I would but boy is it cool.
If you’re like me and working in a Cloud Engineering capacity then you probably have built a DrawIO diagram at some point in your life to describe or define your AWS architecture. Then you have spent countless hours using that diagram to write your Terraform. I’ve built something that will save you those hours and get you started on your cloud journey.
Enter https://drawiototerraform.com. My new tool that allows you to convert your DrawIO AWS Architecture diagrams to Terraform just by uploading them. The process uses a combination of Python and LLM’s to identify the components in your diagram and their relationships, write the base Terraform, analyze the initial Terraform for syntax errors and ultimately test the Terraform by generating a Terraform plan.
All this is then delivered to you as a ZIP file for you to review, modify and ultimately deploy to your environment. By no means is it perfect yet and that is why I am looking for people to test the platform.
If you, or someone you know, is interested in helping me test have them reach out to me on through the website’s support page and I will get them some free credits so that they can test out the platform with their own diagrams.
If you are interested in learning more about the project in any capacity do not hesitate to reach out to me at anytime.
Pre-signed URL’s are used for downloading objects from AWS S3 buckets. I’ve used them many times in the past for various reasons but this idea was a new one. A proof of concept for an API that would create the pre-signed URL and return it to the user.
This solution utilizes an API Gateway and an AWS Lambda function. The API Gateway takes two parameters “key” and “expiration”. Ultimately, you could add another parameter for “bucket” if you wanted the gateway to be able to get objects from multiple buckets.
I used Terraform to create the infrastructure and Python to program the Lambda.
The Terraform will also output a Postman collection JSON file so that you can immediately import it for testing. If this code and pattern is useful for you check it out on my GitHub below.
I’m happy to announce the release of my Discord Bot Framework. A tool that I’ve spent a considerable amount of time working on to help people build and deploy Discord Bots quickly within AWS.
Let me first start off by saying I’ve never released a product. I’ve run a service business and I’m a consultant but I’ve never been a product developer. This release marks my first codebase that I’ve packaged and put together for developers and hobbyists to utilize.
So let’s talk about what this framework does. First and foremost it is not a fully working bot. There are pre-requisites that you must accomplish. The framework holds some example code for commands and message context responses which should be enough to get any Python developer started on building their bot. The framework also includes all of the required Terraform to deploy the bot within AWS.
When you launch the Terraform it will build a Docker image for you and deploy that image to ECR as well as launch the container within AWS Fargate. All of this lives behind a load balancer so that you can scale your bot’s resources as needed although I haven’t seen a Discord bot ever require that many resources!
I plan on supporting this project personally and providing support via email for the time being for anyone who purchases the framework.
Roadmap: – GitHub Actions template for CI/CD – More Bot example code for commands – Bolt on packages for new functionality
I hope that this framework helps people get started on building bots for Discord. If you have any questions feel free to reach out to me at anytime!