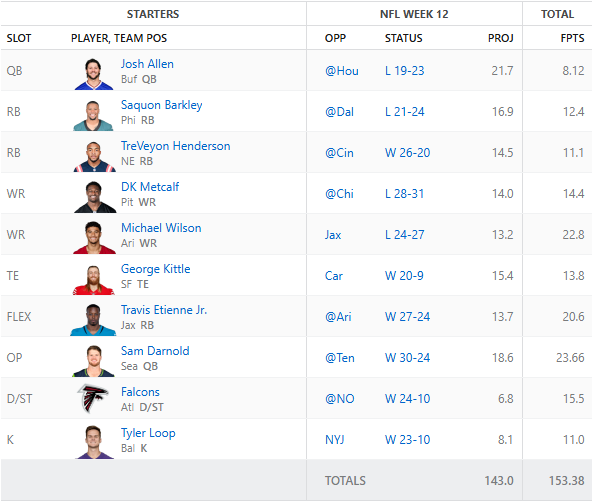
Happy Wednesday. Victory Wednesday that is! Our AI selected correctly this week and we snuck in a tough win that was finalized on Sunday night.
Unfortunately, we lost Zach Ertz on the way. A really nasty low hit took him out for the year. Here is the final scores for our lineup:
Josh Allen came up huge for us. Breece Hall was useless and the Commanders defense might as well have never stepped out on the field. But, a win is a win! We are now in a 3 way tie for first place but will likely take the third seed into the playoffs given our total fantasy points.
Here is the lineup for week 15: We’ve had to make some changes from waivers and I’m hoping the AI selected correctly. We are heading into the part of the season where teams are going to be fighting for playoff spots. I hope that it is taking that into account as it made the waiver picks.
We have some highly projected players this week. What do you think? Will we be able to pull off another win this week?
Well, unfortunately we took a big loss and are now in a three way tie for first place. Here are the actual results:
I think the biggest hit was how poorly Josh Allen played. What is interesting is that I was reviewing his passed performance against Houston and he has had his worst outings of his career there. This week was no different… The other interesting thing is that Saquon Barkley just isn’t the same back as he was last year. He is trending down.
In response to Josh Allen’s poor outing I added a deviation and historical performance analysis against and opponent to the data set so now we have a value like:
I then coded a new tool inside of the AI to reference this data set to assist with its final calculations.
So, when we ask the tool about Josh Allen’s performance against a team we get something like:
Found exactly what you're looking for in Josh Allen's performance data.
Josh Allen vs Kansas City (Week 9, 2025):
- 28.8 fantasy points - That's a STRONG performance!
- He was projected for 22.0 points but exceeded by 6.8 points (+30.9%)
- This was one of his better games this season
Historical Context (2024 vs KC):
- Week 11, 2024: 24.0 fantasy points vs Kansas City
Bottom Line: Josh Allen has performed WELL against Kansas City in recent matchups. In their two most recent meetings:
- 2025 (Week 9): 28.8 points
- 2024 (Week 11): 24.0 points
That's an average of 26.4 fantasy points against KC - well above his season average. Allen seems to rise to the occasion against elite competition like Kansas City. The Chiefs' defense can be vulnerable to mobile QBs who can extend plays, and Allen's dual-threat ability has historically given them problems.
The takeaway: When Allen faces KC, he typically delivers QB1 numbers. That 28.8-point performance this season shows he can still light up even the defending champs!
I need to backload some more historical data yet but that is a problem for a different day. Looking forward, I hope to build my own model based on this data and setup an automated workflow that will include data ingestion and automated model building so that I can consistently build predictions.
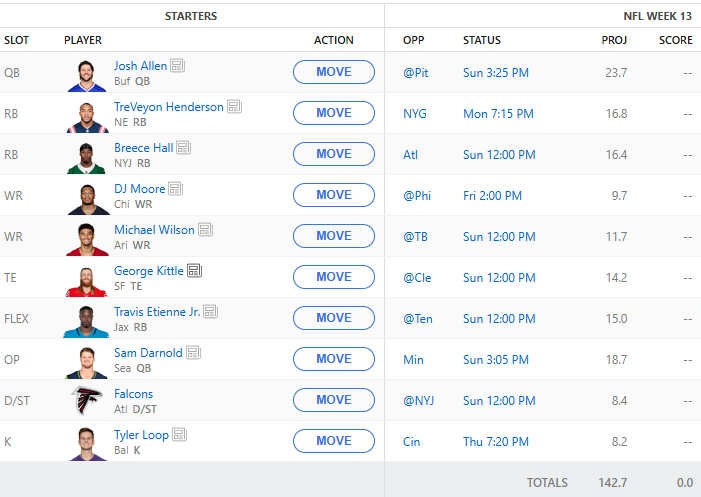
So, on to week 13. We have a bunch of injuries this week to contend with so this lineup will likely be changing once people are reporting. Here is the current lineup:
In other news I built and launched https://gridirondata.com which is an API to reference all of the data I have collected so far.
Unfortunately, its not free. But if you message me about it I’ll probably hook you up!
Well, our win streak was too good to be true. Unfortunately we lost a close one in week 6. It came down to the Monday night games and Sam Darnold just wasn’t able to get it going over the Texans even though the Seahawks still pulled out the win.
Our running back group also did not preform well outside of Josh Jacobs. The loss was by a difference of about 7 points so if anyone had put up another touchdown we could have won.
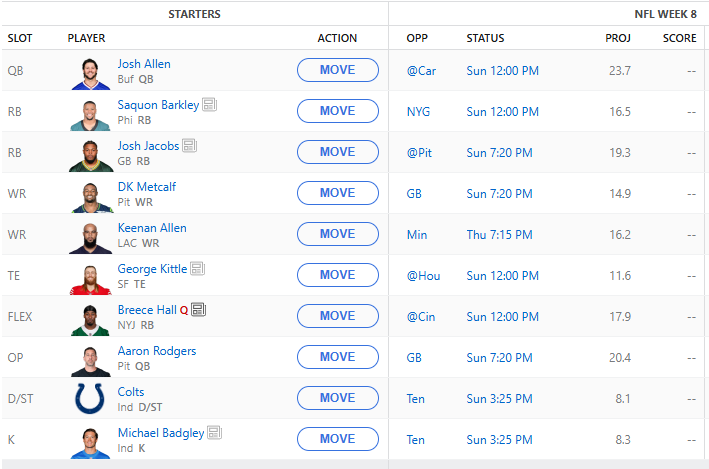
Anyway, on to week week 8. A few byes to contend with but otherwise most of are starts will be playing. The AI suggested grabbing the Colts defense and kicker as they are playing Tennessee. Breece Hall is currently questionable to play so we will have to keep an eye on that but he has a favorable matchup against the Bengals. The current roster is below.
I promised to work on MCP this week but have only made a little bit of progress. I’ve been doing a lot of research on doing it in a cost effective manner as this project makes ZERO dollars and so I can’t afford to setup a bunch of expensive infrastructure. SO – this week I worked on combining the waiver table and the stats table into one table so that we can minimize DynamoDB calls throughout the application. The other thing I did was setup DynamoDB streams which are then converted into text files for each player and placed into an S3 bucket. This is what I think will be the first step in setting up a RAG pipeline so that a model can begin to be more “aware” of current NFL and Fantasy Football landscape.
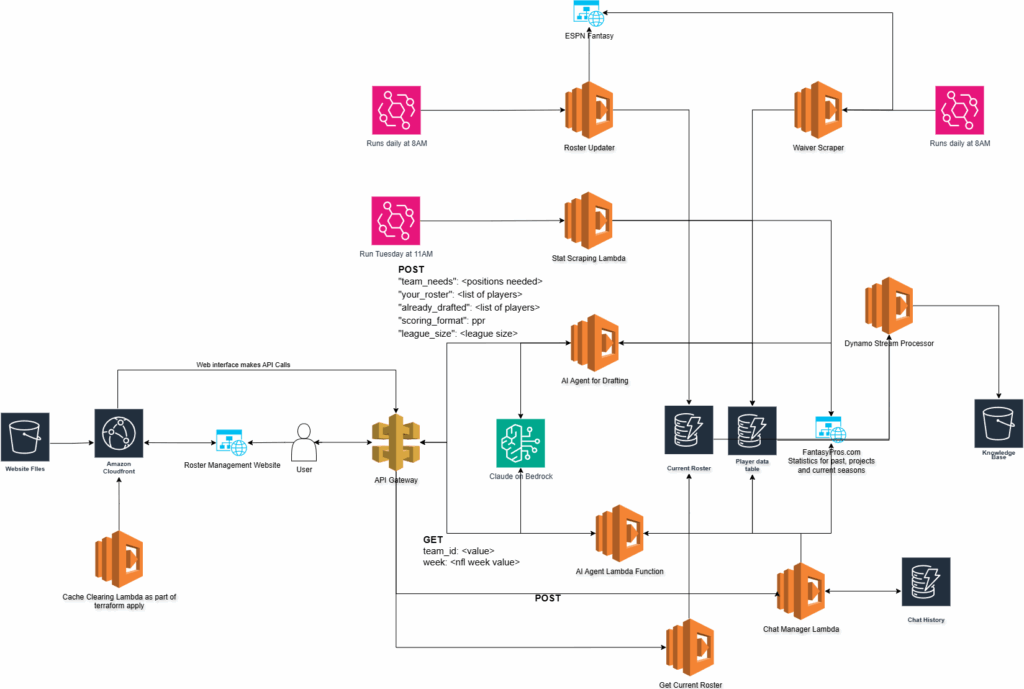
Here is an updated architecture diagram. You’ll notice the S3 bucket on the right side. This is the eventual start of our knowledgebase.
You’ll also notice the waiver table removed. The new player structure looks like this:
{
"player_id": "George Kittle#TE",
"espn_player_id": 3040151,
"player_name": "George Kittle",
"position": "TE",
"seasons": {
"2024": {
"season_totals": {
"MISC_FL": 0,
"MISC_FPTS": 158.6,
"MISC_FPTS/G": 10.6,
"MISC_G": 15,
"MISC_ROST": "99.4%",
"Player": "George Kittle",
"Rank": 1,
"RECEIVING_20+": 21,
"RECEIVING_LG": 43,
"RECEIVING_REC": 78,
"RECEIVING_TD": 8,
"RECEIVING_TGT": 94,
"RECEIVING_Y/R": 14.2,
"RECEIVING_YDS": 1106,
"RUSHING_ATT": 0,
"RUSHING_TD": 0,
"RUSHING_YDS": 0
},
"weekly_stats": {
"1": {
"fantasy_points": 4,
"opponent": "NYJ"
},
"2": {
"fantasy_points": 13.6,
"opponent": "MIN"
},
"4": {
"fantasy_points": 10.5,
"opponent": "NE"
},
"5": {
"fantasy_points": 12.4,
"opponent": "ARI"
},
"6": {
"fantasy_points": 17.8,
"opponent": "SEA"
},
"7": {
"fantasy_points": 9.2,
"opponent": "KC"
},
"8": {
"fantasy_points": 18.8,
"opponent": "DAL"
},
"10": {
"fantasy_points": 11.7,
"opponent": "TB"
},
"12": {
"fantasy_points": 14.2,
"opponent": "GB"
},
"13": {
"fantasy_points": 0.7,
"opponent": "BUF"
},
"14": {
"fantasy_points": 15.1,
"opponent": "CHI"
},
"15": {
"fantasy_points": 6.1,
"opponent": "LA"
},
"16": {
"fantasy_points": 10.6,
"opponent": "MIA"
},
"17": {
"fantasy_points": 11.2,
"opponent": "DET"
},
"18": {
"fantasy_points": 2.7,
"opponent": "ARI"
}
}
},
"2025": {
"injury_status": "ACTIVE",
"jersey_number": "85",
"percent_owned": 98.97,
"pro_team_id": 25,
"season_projections": {
"MISC_FL": 0.5,
"MISC_FPTS": 147.6,
"RECEIVING_REC": 76,
"RECEIVING_TD": 7.5,
"RECEIVING_YDS": 1036.9
},
"team": "SF",
"weekly_outlooks": {
"1": "George Kittle is healthy and wealthy for the 49ers' Week 1 matchup against Seattle after signing a big four-year contract extension in the offseason. Kittle's role as a pass catcher should be intensified early on with WR Brandon Aiyuk (ACL) on the PUP list to begin the campaign and Jauan Jennings (calf, contract) uncertain to suit up against the Seahawks. Kittle is coming off a 78-catch, 1,106-yard, eight-TD 2024 campaign, further cementing his place as one of the NFL's elite producers at tight end. The Seahawks were middle-of-the-pack against the position last year, giving up an average of 51.5 receiving yards per game.",
"2": "George Kittle won't play in San Francisco's Week 2 matchup against New Orleans due to a hamstring injury that landed him on IR. Luke Farrell and Jake Tonges, who caught a TD in Kittle's absence last week against the Seahawks, will be asked to step in at tight end for the 49ers.",
"3": "George Kittle will miss his second straight game for the 49ers in Week 3 against the Cardinals while he remains on IR due to a hamstring injury. Jake Tonges and Luke Farrell should continue to hold down the fort at TE for Kittle until the latter is able to return. Kittle won't be eligible to suit up again until Week 6."
},
"weekly_projections": {
"5": 12.7,
"6": 13.1,
"7": 13.4,
"8": 11.7,
"10": 14.6,
"12": 11.6,
"13": 13.2,
"14": 13.4,
"15": 14.1,
"16": 14.1,
"17": 14.5
},
"weekly_stats": {
"1": {
"fantasy_points": 12.5,
"opponent": "SEA",
"team": "SF",
"updated_at": "2025-10-15T17:40:58.625370"
},
"2": {
"fantasy_points": 12.5,
"opponent": "NO",
"team": "SF",
"updated_at": "2025-09-16T17:08:05.179797"
},
"3": {
"fantasy_points": 12.5,
"opponent": "ARI",
"team": "SF",
"updated_at": "2025-09-23T15:00:13.907272"
},
"4": {
"fantasy_points": 12.5,
"opponent": "JAX",
"team": "SF",
"updated_at": "2025-09-30T15:00:14.035733"
},
"5": {
"fantasy_points": 12.5,
"opponent": "LAR",
"team": "SF",
"updated_at": "2025-10-07T15:00:13.665217"
},
"6": {
"fantasy_points": 12.5,
"opponent": "TB",
"team": "SF",
"updated_at": "2025-10-14T15:00:14.748804"
}
}
}
},
"updated_at": "2025-10-22T18:11:05.039158"
}
I hope to continue to refine this so that it can be used for future seasons. Then we can continue to use the bot into 2026’s season.
Anyway, hopefully I can figure out MCP and the knowledgebase this week. Winter is coming so its time to hunker down and build AWS Architectures!
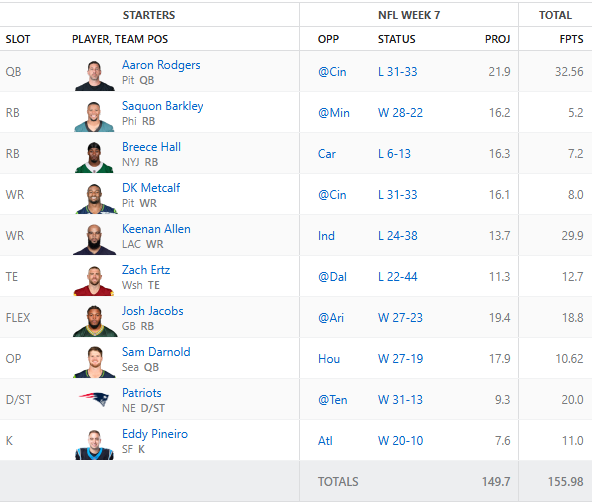
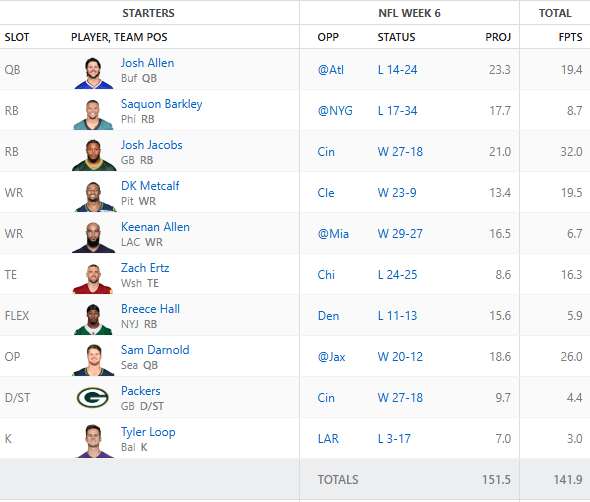
We’re back with the week 6 AI managed fantasy football team and we got another win! The team’s record is now 4-2-0 and sits 3rd in the league.
Here is the final lineup that was fielded for week 6 and the points
There were a couple players on the bench that did better. Keenan Allen and Breece Hall could have been swapped for pretty much anyone on the bench and we would have had a few more points. A win is a win. One thing to note is that we had a game time injury of Dalton Kincaid and I had to pull Zach Ertz in at the last minute to avoid getting a zero.
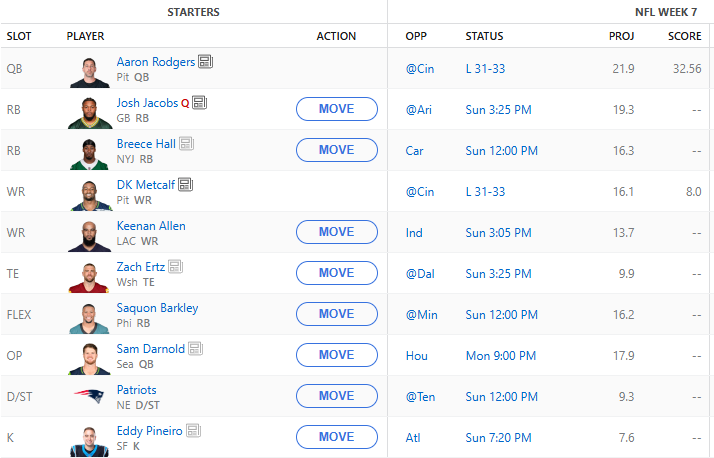
For week 7 we are starting to see both injury and bye weeks happening. The AI will have to make some pretty deep roster moves in order to fill the gaps. Here is the initial starting lineup:
Because of the BYE weeks we are picking up Aaron Rodgers who put up a good game against Cincinnati last night. DK did not have a great night last night. We picked up the Patriots defense as well as Eddy Pineiro to fill in some slots. I think the Patriots against Tennessee will be an interesting matchup given that the Titans fired their head coach. Mike Vrabel has the Patriots firing again and hopefully he can shut them out and we can put up some big points!
From a tech perspective, I’m slowly putting together an MCP server to help create some efficiencies when working with the DynamoDB tables. Hopefully, if we can handle that, the overall application response time will be faster. If I wasn’t traveling AGAIN this weekend I would have made it a hackathon. Hopefully for week 8!
After a heartbreaking (lol) loss in week one, our agent is back with its picks for week two!
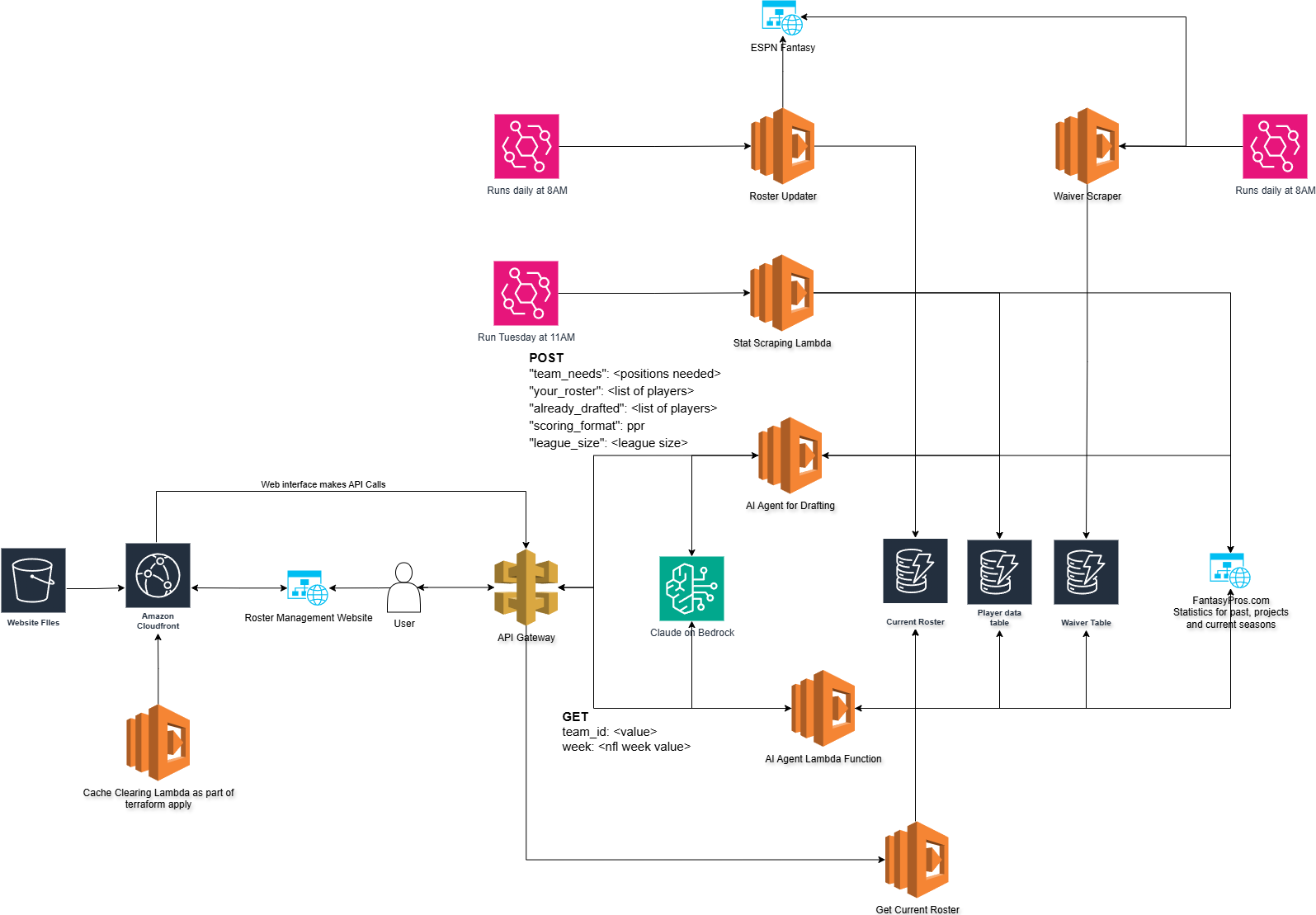
But, before we start talking about rosters and picks and how I think AI is going to lose week two, let’s talk about the overall architecture of the application.
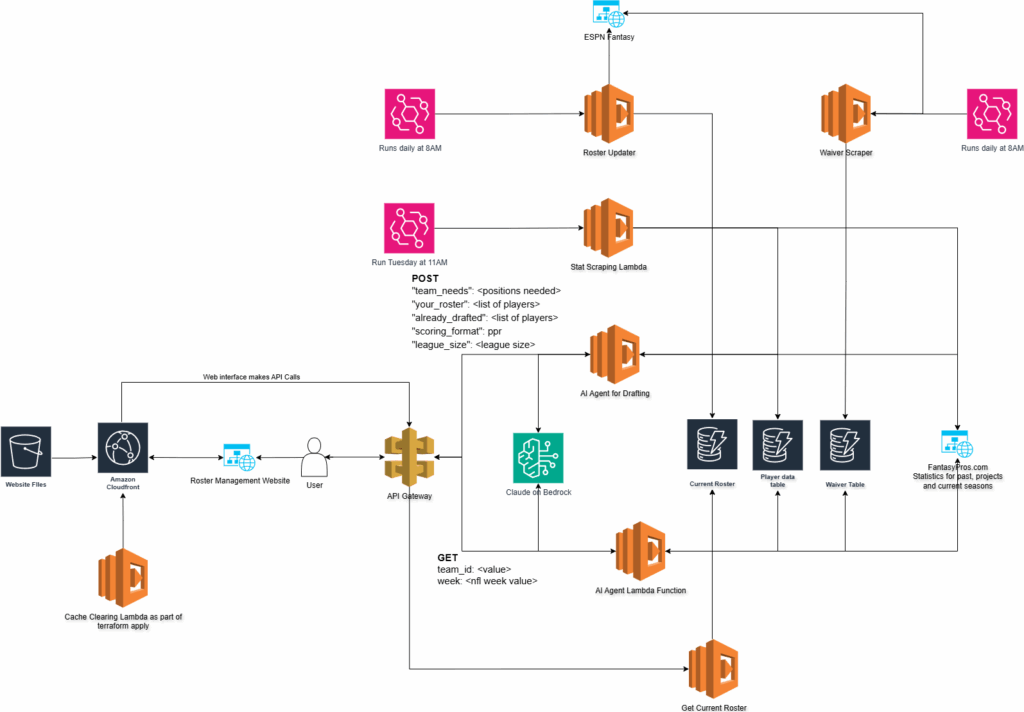
Current Architecture diagram
You may notice that after my post on Tuesday I have substantially reduced the data storage. I’m now using three DynamoDB tables to handle everything.
Current Roster – This table is populated by an automated scraper that pulls the rosters for all the teams in the league.
Player Data Table – This table populates all the historical data from the draft as well as projected stats for the 2025 season. It also holds the actual points received after the week has completed.
Waiver Table – this is probably the most notable addition to the overall Agent. This table is populated by both ESPN and FantasyPros
The waiver wire functionality is a massive addition to the Agent. It now has the ability to know what players are available for me to add to the team. If we combine that with the player stats in the Player Data Table we can get a clear picture as to how the player MIGHT preform on a week to week basis.
The waiver table is populated by a lambda function that goes out and scrapes the ESPN Fantasy Platform. It is quite involved code as there is no API for ESPN. I’m still not sure why they don’t build one. It seems like an easy win for them especially as they get into more sports gambling. You can read the code here. This Lambda function runs on a CRON every day so that the Agent always has daily updated data.
The other major addition is a web interface. I realized that accessing this via a terminal is great but, it would be way more interesting to have something to look at. Especially if I am away from the computer.
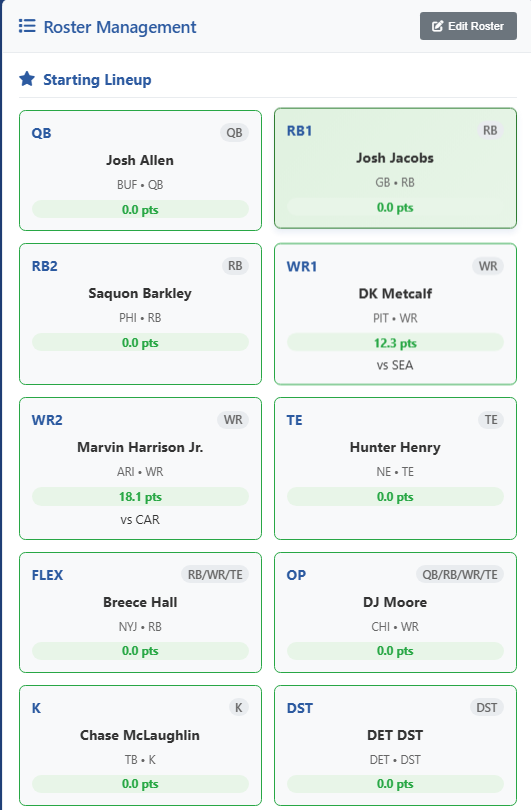
The web interface consists of a display of the roster:
Roster Screenshot
There are a couple things I need to fix. You’ll notice that a few players “have points” this is a problem with the data in the Player Data Table from when I was merging all the sources. Ideally, this will display the points the player has received for the week. Eventually I would like to add some live streaming of the point totals.
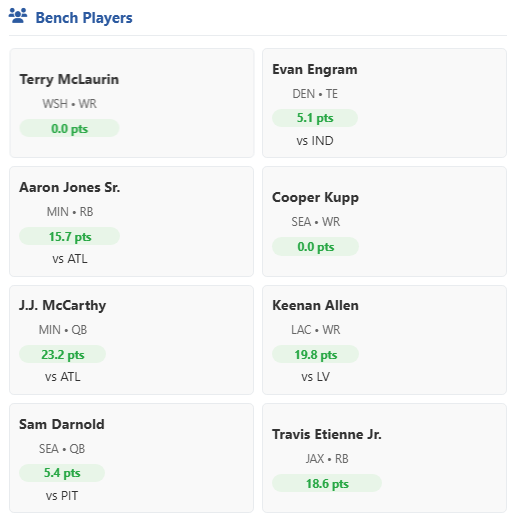
Bench Players
It also displays the bench (notice the same data glitch). On my list of things to do is to make these boxes drag and drop and auto update the roster table so that we can move players around. I also want to add their projections to each block so I can see the projected points per week for each player.
The BEST part (in my opinion) is the prediction functionality. There is a box that we can choose which week to get a prediction for and then it will return output from the agent.
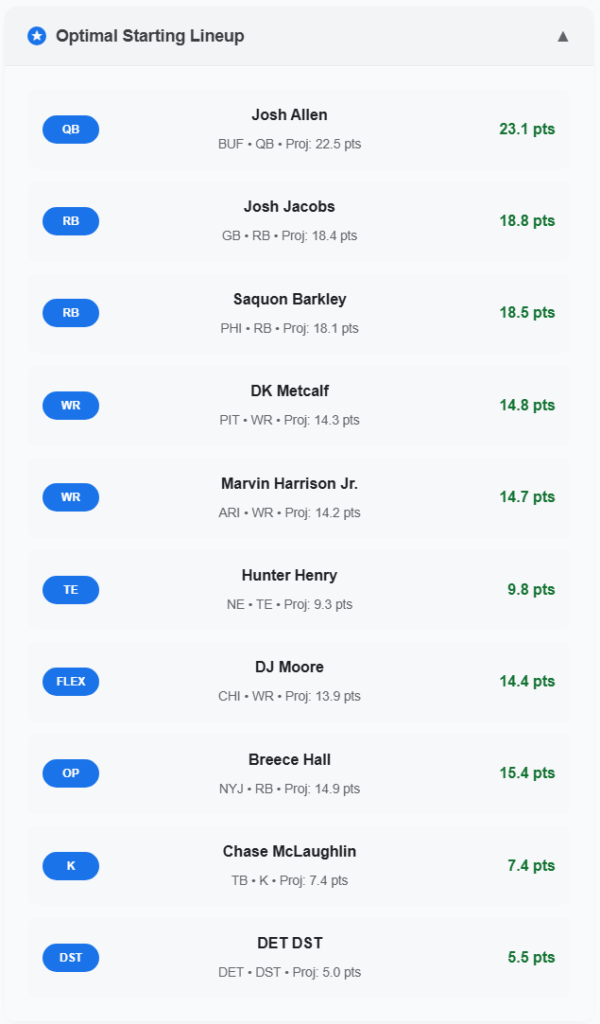
So, let’s take a look at week two!
Optimal Week 2 Lineup
Here is a screenshot of the week two optimal lineup. This is the lineup I will be starting for week two unless one of my tight-ends becomes healthy. With George Kittle on injured reserve and Evan Engram also questionable, the AI suggested picking up Hunter Henry.
The Agent will also provide up with some waiver targets as well as matchup analysis
It will also output the full response for each week. Here is the full text of what the Agent has predicted for week two:
LINEUP OPTIMIZATION FOR WEEK 2
Starting Lineup Strategy: – Josh Allen (QB): Elite QB1 with 38.8 points in Week 1, facing NYJ defense that allowed significant passing yards. His 2024 average of 31.85 and strong 2025 projection make him a must-start. – Josh Jacobs (RB1): Top projected RB at 18.4 points, facing Washington at home. Green Bay’s new offensive system should benefit Jacobs significantly. – Saquon Barkley (RB2): Projected 18.1 points against Kansas City. His 2024 average of 15.93 and strong 2025 projection of 273.2 season points make him a core play. – DK Metcalf (WR1): Highest projected WR at 14.3 points. Pittsburgh vs Seattle should be a competitive game with passing volume. – Marvin Harrison Jr. (WR2): Rookie with 14.2 projection facing Carolina. His 154.5 season projection suggests breakout potential. – Hunter Henry (TE): Best available TE option at 9.3 projected points with Kittle on IR and Engram questionable. – DJ Moore (FLEX): Solid 13.9 projection against Detroit. Chicago’s passing game should see volume in what could be a high-scoring affair. – Breece Hall (OP): Critical OP selection at 14.9 projected points. Hall offers RB1 upside against Buffalo, and using an RB in the OP slot provides higher floor than WR options.
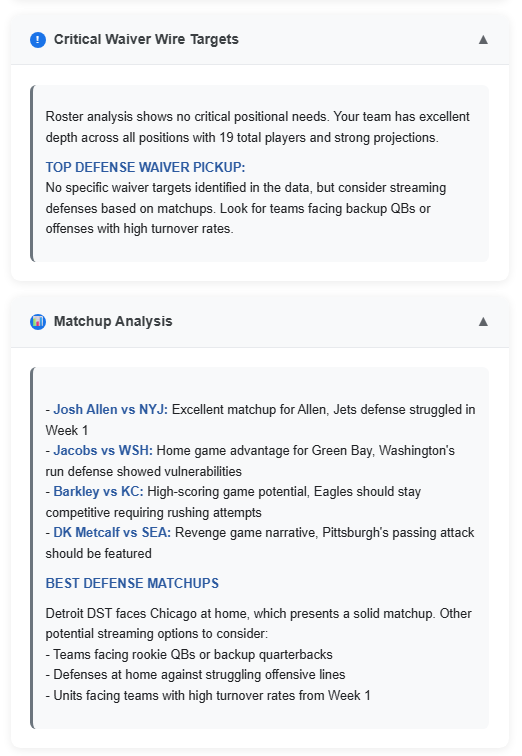
CRITICAL WAIVER WIRE TARGETS:
Roster analysis shows no critical positional needs. Your team has excellent depth across all positions with 19 total players and strong projections.
TOP DEFENSE WAIVER PICKUP: No specific waiver targets identified in the data, but consider streaming defenses based on matchups. Look for teams facing backup QBs or offenses with high turnover rates.
INJURY CONCERNS: – George Kittle: On Injury Reserve, unavailable for Week 2 – Evan Engram: Listed as Questionable, monitor his status throughout the week
MATCHUP ANALYSIS: – Josh Allen vs NYJ: Excellent matchup for Allen, Jets defense struggled in Week 1 – Jacobs vs WSH: Home game advantage for Green Bay, Washington’s run defense showed vulnerabilities – Barkley vs KC: High-scoring game potential, Eagles should stay competitive requiring rushing attempts – DK Metcalf vs SEA: Revenge game narrative, Pittsburgh’s passing attack should be featured
BEST DEFENSE MATCHUPS
Detroit DST faces Chicago at home, which presents a solid matchup. Other potential streaming options to consider: – Teams facing rookie QBs or backup quarterbacks – Defenses at home against struggling offensive lines – Units facing teams with high turnover rates from Week 1
WAIVER PRIORITY: 1. Streaming Defense: Look for defenses with favorable Week 3 matchups 2. Handcuff RBs: Target backup RBs for your elite runners (Jacobs, Barkley, Hall) 3. High-Upside WRs: Monitor snap counts and target shares from Week 2 for emerging receivers
Final Comments: Your roster is exceptionally deep and well-constructed. The OP position selection of Breece Hall provides excellent upside, as RBs typically offer higher floors than WRs in flex positions. Focus on matchup-based streaming for defense and monitor the waiver wire for breakout players rather than addressing positional needs. Your core lineup projects for strong Week 2 performance with multiple players having 15+ point upside.
What’s Next?
So we have a pretty solid week two prediction. Josh Allen and Saquon Barkley I have faith in. The rest of the team is hit or miss. Chicago faces Detroit at Ford Field (Go Lions!) and both teams lost week one. But Ben Johnson facing his old team for the first time has me nervous.
This brings up a few of my to-dos for the overall program.
Defensive matchups – I need to get data for the Defenses to find the best matchups week to week. Having a good defense play is an easy way to get an advantage every week.
Add authentication – I added a really simple authentication method to the code just for the time being. But, it would be nice to have a Single Sign On or something a little bit more secure.
Drag-n-drop interface – I need to add functionality to be able to modify the roster on the web interface. It would be nice if this could also update ESPN.
Slow Output – I’m always looking for ways to optimize the Agent’s output. Currently it takes about 45 seconds to a minute to return the output.
Thoughts? I hope this series is entertaining. If you have ideas for the Agent please comment below or shoot me a message somewhere!
Last year I attempted to program a Fantasy Football draft assistant which took live data from ESPN’s Fantasy Platform. Boy was that a mistake…
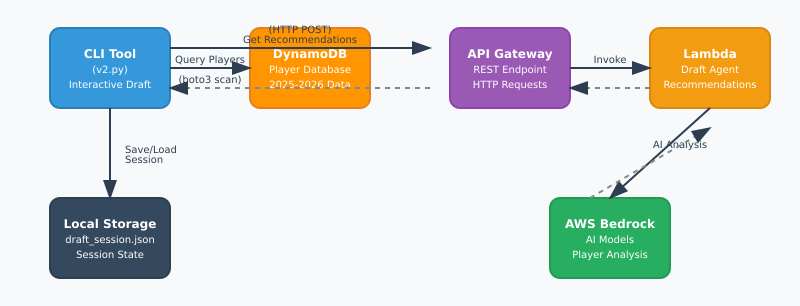
First of all, shame on ESPN for not having an API for their Fantasy sports applications. The reverse engineered methods were not fast enough nor were they reliable. So, this year I took a new approach to building out a system for getting draft pick recommendations for my team.
I also wanted to put to use the example architecture and code I wrote the other day for the Strands SDK to work so I utilized it to build an API which would utilize the AWS Bedrock platform to analyze data and and ultimately return the best possible picks.
Here is a simple workflow of how the tool works:
I generated this with Claude AI. It is pretty OK.
The first problem I encountered was getting data. I needed two things: 1. Historical data for players 2. Projected fantasy data for the upcoming season
The historical data provides information about the players past season and the projections are for the upcoming season, obviously. The projections are useful because of any incoming rookies.
In the repository I link below I put a scripts to scrape FantasyPros for both the historical and projected data. It stores them in separate files in case you want to utilize them in a different way. There is also a script to combine them into one data source and ultimately load them into a DynamoDB table.
The most important piece of the puzzle was actually simulating the draft. I needed to create a program that would be able to track the other team’s draft picks as well as give me the suggestions and track my teams picks. This is the heart of the repository and I will be using it to get suggestions and track the draft for this coming season.
Through the application, when you issue the “next” command the application will send a request to the API with the current situation of the draft. The payload looks like this:
The “team_needs” key represents the current number of players remaining for each position. The “your_roster” position is all of the current players on my team. The other important key is “already_drafted”. This key sends all of the drafted players to the AI agent so it knows who NOT to recommend.
The application goes through all of the picks and you are able to manually enter each of the other teams picks until the draft is complete.
I’ll post an update after my draft on August 24th with the team I end up with! I still will probably lose in my league but this was fun to build. I hope to add in some sort of week-to-week management of my team as well as a trade analysis tool in the future. It would also be cool to add in some sort of analysis that could send updates to my Slack or Discord.
If you have other ideas message me on any platform you can find me on!
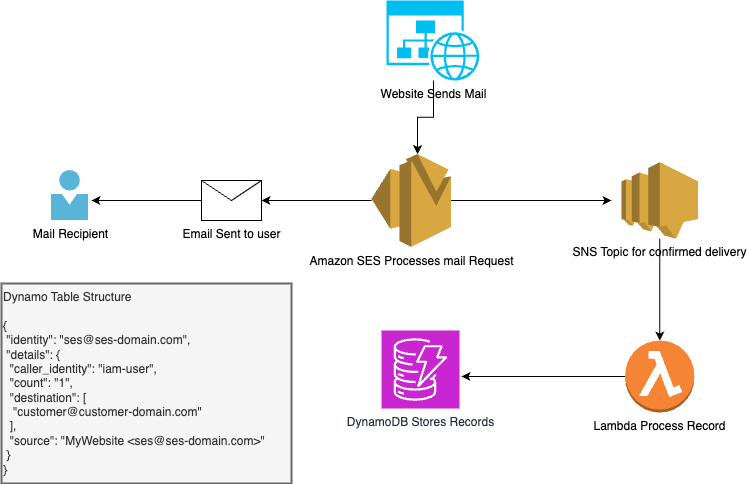
I love AWS. But one thing they don’t do is build complete tools. SES is one of them. I recently started getting emails about high usage for one of the identities that I have set up for SES. I would assume that there was a way to track usage within CloudWatch but for the life of me I couldn’t find one. So I guess that means I need to build something.
The idea here is pretty simple, within SES identities you can set up a notification. So, I created an SNS topic and subscribed all delivery notifications to the topic. Then, subscribe a Lambda function to the topic. The lambda function acts as the processor for the records then formats them in a usable way and puts them into DynamoDB. I used the identity as the primary key. The result is a simple application architecture like the below image.
Every time an email is delivered the lambda function processes the event and checks the DynamoDB table to see if we have an existing record. If the identity is already present in the table it returns the “count” value so that we can increment the value. The “destination” value appends the destination of the email being sent. Below is a sample of the code I used to put the object into the DynamoDB Table.
def put_dynamo_object(dynamo_object):
count = str(dynamo_get_item(dynamo_object))
if count == None or count == 0:
count = str(1)
else:
count = int(count) + 1
# get email address from the long string
source_string = dynamo_object['source']
email_match = match = re.search(r'[\w.+-]+@[\w-]+\.[\w.-]+', source_string)
email = match.group(0)
try:
table.update_item(
Key={
'identity': email
},
AttributeUpdates={
'details': {
'Value': {
'caller_identity': dynamo_object['caller_identity'],
'source': dynamo_object['source'],
'destination': dynamo_object['destination'],
'count': str(count)
}
}
}
)
return True
except ClientError as e:
print("Failed to put record")
print(e)
return False
If you want to use this code feel free to reach out to me and I will share with you the Terraform to deploy the application and as always, reach out with questions or feedback!
I think its pretty obvious that I love DynamoDB. It has become one of my favorite AWS Services and I use it almost every day at work and am getting better at using it for my personal projects as well.
I had a client approach me about getting logs from a Cloudfront Distribution. Cloudfront has a native logging function that spits out .GZ files to an S3 bucket. My client doesn’t have any sort of log ingestion service so rather than build one I decided we could parse the .GZ files and store the data into a DynamoDB table. To accomplish this I created a simple lambda:
import boto3
import gzip
import uuid
from datetime import datetime
from datetime import timedelta
import time
from botocore.exceptions import ClientError
#Creates a time to live value
def ttl_time():
now = datetime.now()
ttl_date = now + timedelta(90)
final = str(time.mktime(ttl_date.timetuple()))
return final
#Puts the log json into dynamodb:
def put_to_dynamo(record):
client = boto3.resource('dynamodb', region_name='us-west-2')
table = client.Table('YOUR_TABLE_NAME')
try:
response = table.put_item(
Item=record
)
print(response)
except ClientError as e:
print("Failed to put record")
print(e)
return False
return True
def lambda_handler(event, context):
print(event)
s3_key = event['Records'][0]['s3']['object']['key']
s3 = boto3.resource("s3")
obj = s3.Object("YOUR_BUCKET", s3_key)
with gzip.GzipFile(fileobj=obj.get()["Body"]) as gzipfile:
content = gzipfile.read()
#print(content)
my_json = content.decode('utf8').splitlines()
my_dict = {}
for x in my_json:
if x.startswith("#Fields:"):
keys = x.split(" ")
else:
values = x.split("\t")
for key in keys:
if key == "#Fields:":
pass
else:
for value in values:
my_dict[key] = value
x = 0
for item in keys:
if item == "#Fields:":
pass
else:
my_dict[item] = values[x]
x +=1
print('- ' * 20)
myuuid = str(uuid.uuid4())
print(myuuid)
my_dict["uuid"] = myuuid
my_dict['ttl'] = ttl_time()
print(my_dict)
if put_to_dynamo(my_dict) == True:
print("Successfully imported item")
return True
else:
print("Failed to put record")
return False
This lambda runs every time there is an S3 object created. It takes grabs the .GZ file and parses it into a dictionary that can be imported into DynamoDB. One other thing to note is that I append a UUID so that I can help track down errors.
I wrote a simple front end for the client to grab records based on date input which writes the logs to a CSV so they can parse them on their local machines. I have a feeling we will be implementing a log aggregation server soon!
If this code helps you please share it with your friends and co-workers!
Have you ever wanted to migrate data from one Dynamo DB table to another? I haven’t seen an AWS tool to do this so I wrote one using Python.
A quick walk through video
import sys
import boto3
## USAGE ############################################################################
## python3 dynamo.py <Source_Table> <destination table> ##
## Requires two profiles to be set in your AWS Config file "source", "destination" ##
#####################################################################################
def dynamo_bulk_reader():
session = boto3.session.Session(profile_name='source')
dynamodb = session.resource('dynamodb', region_name="us-west-2")
table = dynamodb.Table(sys.argv[1])
print("Exporting items from: " + str(sys.argv[1]))
response = table.scan()
data = response['Items']
while 'LastEvaluatedKey' in response:
response = table.scan(ExclusiveStartKey=response['LastEvaluatedKey'])
data.extend(response['Items'])
print("Finished exporting: " + str(len(data)) + " items.")
return data
def dynamo_bulk_writer():
session = boto3.session.Session(profile_name='destination')
dynamodb = session.resource('dynamodb', region_name='us-west-2')
table = dynamodb.Table(sys.argv[2])
print("Importing items into: " + str(sys.argv[2]))
for table_item in dynamo_bulk_reader():
with table.batch_writer() as batch:
response = batch.put_item(
Item=table_item
)
print("Finished importing items...")
if __name__ == '__main__':
print("Starting Dynamo Migrater...")
dynamo_bulk_writer()
print("Exiting Dynamo Migrator")
The process is pretty simple. First, we get all of our data from our source table. We store this in a list. Next, we iterate over that list and write it to our destination table using the ‘Batch Writer’.
The program has been tested against tables containing over 300 items. Feel free to use it for your environments! If you do use it, please share it with your friends and link back to this article!
I have a workflow that creates a record inside of a DynamoDB table as part of a pipeline within AWS. The record has a primary key of the Code Pipeline job. Later in the pipeline I wanted to edit that object to append the status of resources created by this pipeline.
In order to do this, I created two functions. One that first returns the item from the table and the second that actually does the update and puts the updated item back into the table. Take a look at the code below and utilize it if you need to!
import boto3
from boto3.dynamodb.conditions import Key
def query_table(id):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('XXXXXXXXXXXXXX')
response = table.query(
KeyConditionExpression=Key('PRIMARYKEY').eq(id)
)
return response['Items']
def update_dynanmo_status(id, resource_name, status):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('XXXXXXXXXXXXX')
items = query_table(id)
for item in items:
# Do your update here
response = table.put_item(Item=item)
return response