I’ve finally been tasked with a Generative AI project to work on. I’ve done this workflow manually with ChatGPT in the past and it works quite well but, for this project, the requirement was to use Amazon Web Services’ new product “AWS Bedrock”.
The workflow takes in some code and writes a technical document to support a clear English understanding of what the code is going to accomplish. Using AWS Bedrock, the AI will write the document and output it to an S3 bucket.
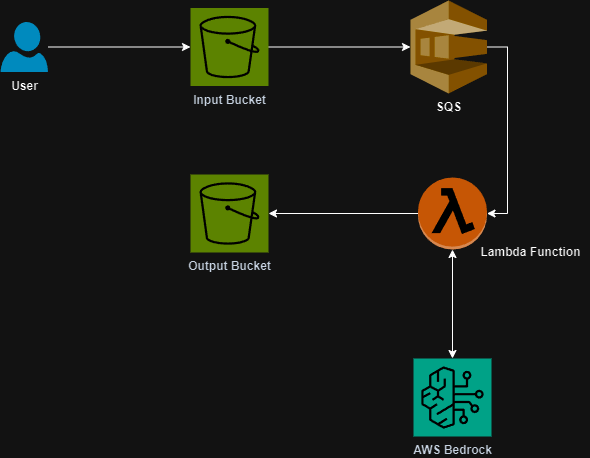
The architecture involves uploading the initial code to an S3 Bucket which will then send the request to an SQS queue and ultimately trigger a Lambda to prompt the AI and fulfill the output upload to a separate S3 bucket. Because this was a proof of concept, the Lambda function was a significant compute resource however going forward I am going to look at placing this code into a Docker container so that it can scale for larger code inputs.
Here is the architecture diagram:
Let’s take a look at some of the important code. First is the prompt management. I wrote a function that will take input of the code as well as a parameter of “prompt_type”. This will allow the function to be scalable to accommodate other prompts in the future.
def return_prompt(code, prompt_type):
if prompt_type == "testPrompt":
prompt1 = f"Human: <your prompt>. Assistant:"
return prompt1The important thing to look at here is the format of the message. You have to include the “Human:” and the “Assistant:”. Without this formatting, your API call will error.
The next bit of code is what we use to prompt the Bedrock AI.
prompt_to_send = prompts.return_prompt(report_file, "testPrompt")
body = {
"prompt": prompt_to_send,
"max_tokens_to_sample": 300,
"temperature": 0.1,
"top_p": 0.9
}
accept = 'application/json'
contentType = 'application/json'
# Return Psuedo code
bedrock_response = h.bedrock_actions.invoke_model(json.dumps(body, indent=2).encode('utf-8'), contentType, accept, modelId=modelid) def invoke_model(body, contentType, accept, modelId):
print(f"Body being sent: {body}")
try:
response = bedrock_runtime.invoke_model(
body=body,
contentType=contentType,
accept=accept,
modelId=modelId
)
return response
except ClientError as e:
print("Failed to invoke Bedrock model")
print(e)
return FalseThe body of our request is what configures Bedrock to run and create a response. These values can be tweaked as follows:
max_tokens_to_sample: This specifies the number of tokens to sample in your request. Amazon recommends setting this to 4000
TopP: Use a lower value to ignore less probable options.
Top K: Specify the number of token choices the model uses to generate the next token.
Temperature: Use a lower value to decrease randomness in the response.
You can read more about the inputs here.
If you want to see more of this code take a look at my GitHub repository below. Feel free to use it wherever you want. If you have any questions be sure to reach out to me!
Leave a Reply