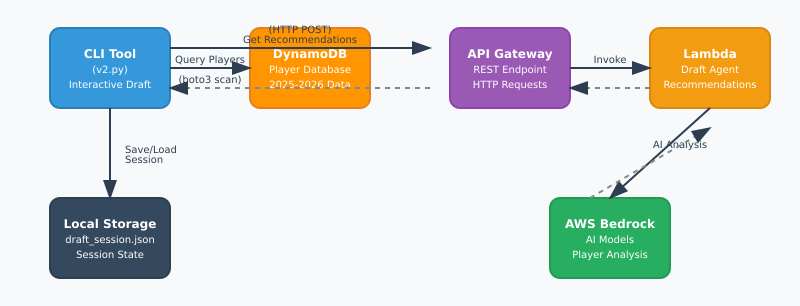
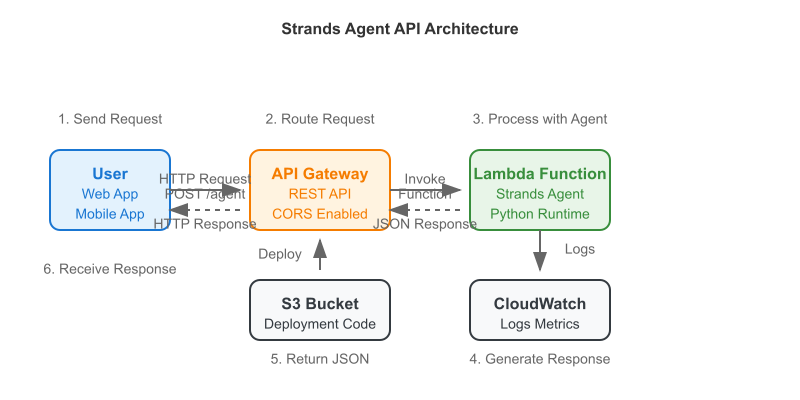
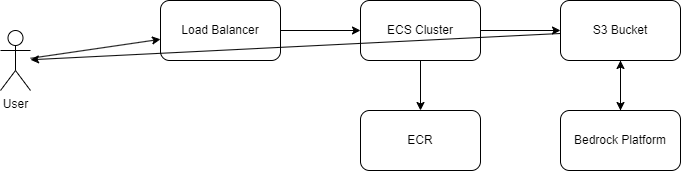
The last you heard from me I was building a drafting agent for Fantasy Football. Well, the draft has finished and my roster is set. Behold, the Fantasy Football AI drafted team for my 8 team, PPR league.
STARTING LINEUP
QB – Josh Allen (BUF)
RB – Saquon Barkley (PHI)
RB – Josh Jacobs (GB)
WR – Terry McLaurin (WSH)
WR – DJ Moore (CHI)
TE – George Kittle (SF)
FLEX – Breece Hall (NYJ)
OP – Sam Darnold (SEA)
D/ST – Lions (DET)
K – Chase McLaughlin (TB)
BENCH
WR – DK Metcalf (PIT)
WR – Marvin Harrison Jr. (ARI)
TE – Evan Engram (DEN)
RB – Aaron Jones Sr. (MIN)
WR – Cooper Kupp (SEA)
QB – J.J. McCarthy (MIN)
WR – Keenan Allen (LAC)
RB – Travis Etienne Jr. (JAX)
Now, I have also added another feature to the overall solution which is to include a week to week manager I’m calling the “coach”. I built a database that contains the 2024 statistics for each player and who they played against. I’m also scraping FantasyPros.com as well for future projections still.
I added a new Lambda function and API call to my architecture so that I can send a request to the AI Agent to build out my ideal weekly roster.
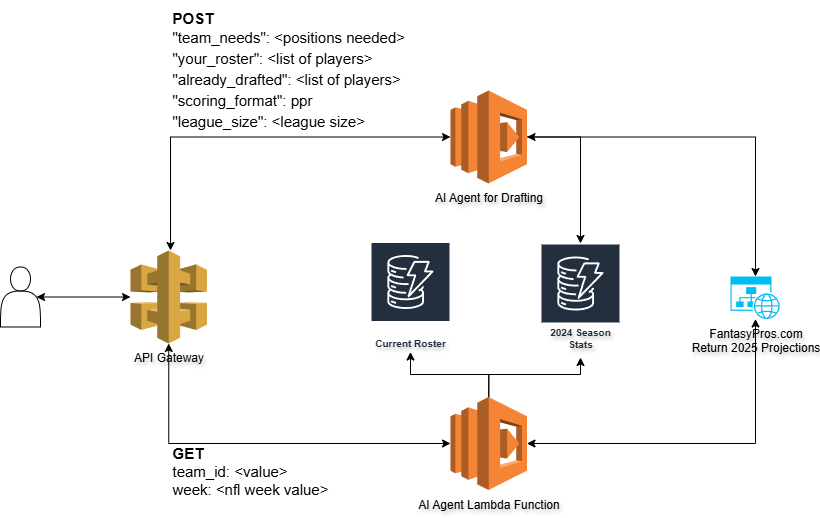
The roster I posted above is what I will be starting for week 1. The agent also provides some context as to why it selected each player.
🏈 Fantasy Lineup for Team 1, Week 1
==================================================
🏆 STARTING LINEUP:
QB: Josh Allen (BUF) 23.4 pts
RB: Saquon Barkley (PHI) 19.9 pts
RB: Josh Jacobs (GB) 15.5 pts
WR: Terry McLaurin (WAS) 11.1 pts
WR: DJ Moore (CHI) 12.5 pts
TE: George Kittle (SF) 10.6 pts
FLEX: Breece Hall (NYJ) 11.5 pts
OP: Sam Darnold (SEA) 18.6 pts
K: Chase McLaughlin (TB) 8.5 pts
DST: Lions (DET) 9.2 pts
💯 TOTAL PROJECTED: 145.4 points
📋 BENCH (Top 5):
WR: Keenan Allen 7.6 pts
WR: DK Metcalf 8.6 pts
WR: Marvin Harrison Jr. 9.5 pts
WR: Cooper Kupp 9.0 pts
RB: Aaron Jones Sr. 12.8 pts
💡 COACH ANALYSIS:
==================================================
Made one key adjustment to the computed lineup: replaced
Keenan Allen with DJ Moore at WR2. While Allen showed
decent recent form (9.325 avg last 4 games), DJ Moore is
the higher-drafted talent with WR1 upside who should be
prioritized in Week 1. Moore's lack of 2024 data likely
indicates injury, but his talent level and role in
Chicago's offense make him the better play. The rest of
the lineup is solid: Allen/Darnold QB combo maximizes
ceiling, Barkley/Jacobs/Hall provide strong RB production,
McLaurin offers consistency at WR1, and Kittle remains a
reliable TE1. Lions DST should perform well at home, and
McLaughlin provides steady kicking in Tampa Bay's offense.
==================================================There are still some gaps I need to fill with the data set as D.J. Moore did play in 2024 so I’m likely missing some data sets. I also have plans to build a “general manager” who can scan available players and find maybe some hidden gems on a week to week basis.
Finally, command line tools are fun but, I think the solution needs a web interface so watch for updates on that. The coach will inevitably automated and send me a report on the weeks performance as well as suggestions for the following week.
If you like Fantasy Football and technology follow along to see how this team performs throughout the season!
All the code is available here on GitHub: https://github.com/avansledright/fantasy-football-agent