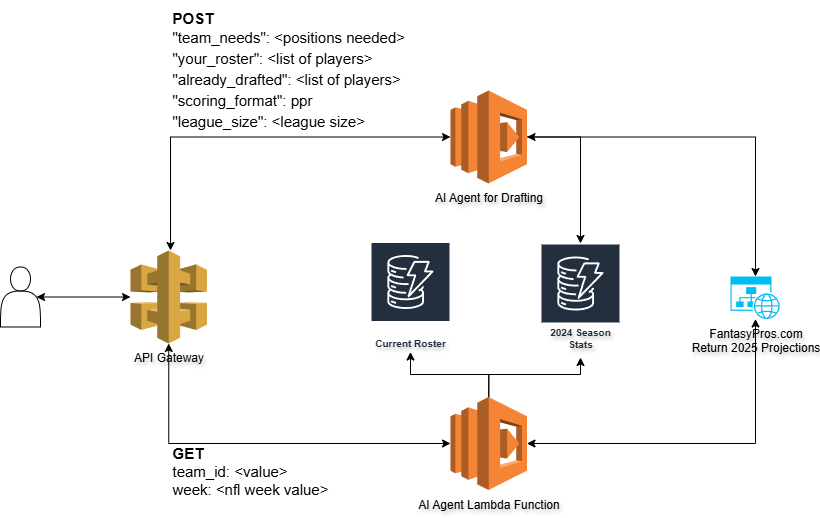
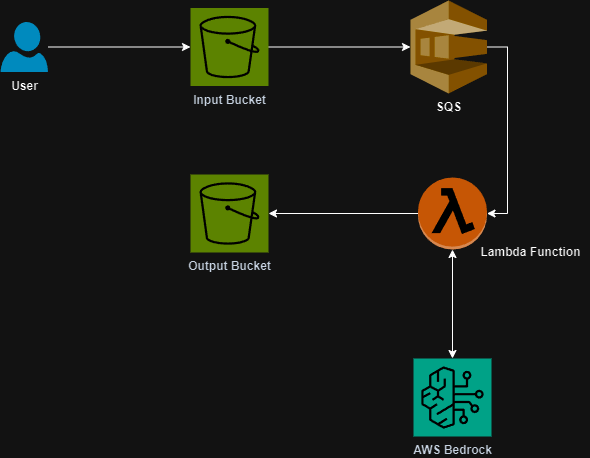
I think one of the biggest time sucks is getting a vague alert or issue and not having a clue on where to start with troubleshooting.
I covered this in the past when I built an agent that can review your AWS bill and find practical ways to save money within your account. This application wasn’t event driven but rather a container that you could spin up when you needed a review or something you could leave running in your environment. If we take a same read-only approach to building an AWS Agent we can have have a new event driven teammate that helps us with our initial troubleshooting.
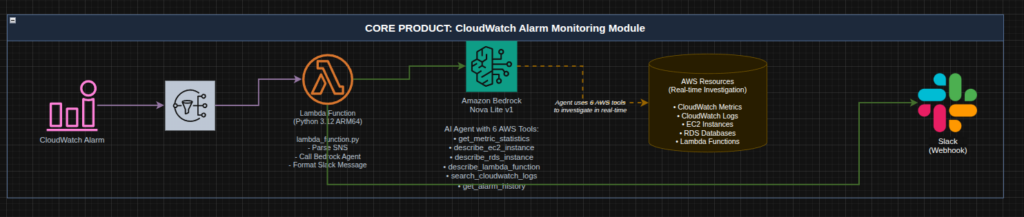
The process flow is straight forward:
- Given a Cloudwatch Alarm
- Send a notification to SNS
- Subscribe a Lambda function to the topic (this is our teammate)
- The function utilizes the AWS Nova Lite model to investigate the contents of the alarm and utilizes its read only capabilities to find potential solutions
- The agent sends its findings to you on your preferred platform
For my environment I primarily utilize Slack for alerting and messaging so I built that integration. Here is an architecture diagram:
When the alarm triggers we should see a message in Slack like:

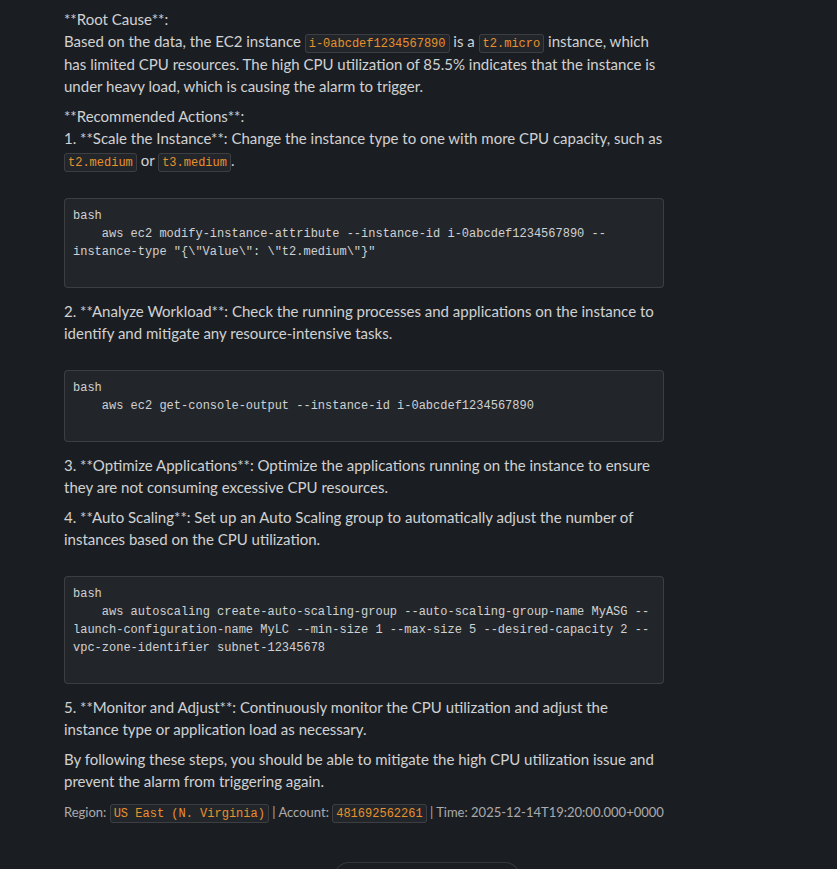
The AI is capable of providing you actionable steps to either find the root cause of the problem or in some cases, present you with steps to solve the problem.
This workflow significantly reduces your troubleshooting time and by reducing the troubleshooting time it reduces your downtime.
So, if this is something you are interested in deploying I have created a Terraform module so you can quickly deploy it into your own environment to reduce your troubleshooting steps!
Check it out here: https://aiopscrew.com
If you have questions feel free to reach out to me at anytime!