“A Fever You Can’t Sweat Out – 20th Anniversary Deluxe” is an album that came out? Wow. I remember seeing Panic! as a teenager…
I stayed away from AI for a long time. I think a lot of people in my field were nervous about security, bad code, incorrect information and much more. In the early days of ChatGPT it was easy to have the AI hallucinate and come up with some nonsense. While its still possible for this to happen I found a workflow that has helped me build applications and proof of concept work very quickly.
First – I have always given AI tasks that I can do myself.
Second – If I can’t do a task, I need to learn about it first.
These aren’t really rules, but, things I think about when I’m building out projects. I won’t fall victim to the robot uprising!
Let’s talk about my workflows.
Tools:
– Claude (Web)
– Claude Code
– Gemini
– Gemini CLI
– ChatGPT
– Todoist
I pay for Claude and I have subscriptions to Gemini Pro through my various GSuite Subscriptions. ChatGPT I use for free. ToDoist is my to do app of choice. I’ve had the subscription since back in my Genius Phone Repair days to manage all of the stores and their various tasks.
The Flow
As with most of you, I’m sure you get ideas or fragments of ideas at random times. I put these into ToDoist where I have a project called “Idea Board” its basically a simplified Kanban board with three columns:
Idea | In progress | Finished
The point of this is to track things and get them out of my brain to free up space in there everything else that happens in my life. I utilize the “In Progress” column for when I’m researching or actually sitting down to process the idea with more detail. Finally, the “Finished” column is utilize for either ideas that I’m not going to work on or ideas that have turned into full projects. This is not the part of the project where I actually detail out the project. It’s just a landing place for ideas.
The next part of the flow is where I actually detail out what I want to do. If you have been utilizing Claude Code or Gemini CLI or Codex you know that input is everything and it always has been since AI became consumer ready. I generally make a folder on my computer and start drafting my ideas with more detail into markdown files. If we look at CrumbCounts.com as an example, I started with simply documenting out the problem I was trying to solve:
Calculate the cost for this recipe.
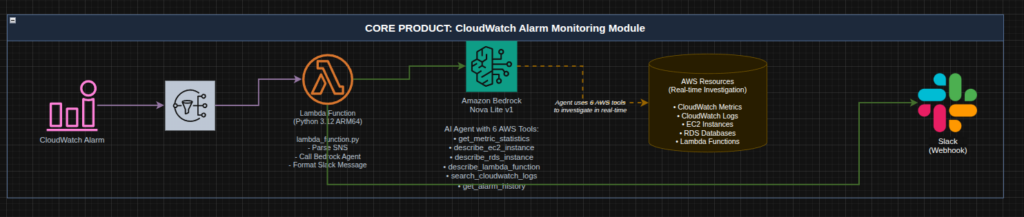
In order to do that we then need to put a bunch of pieces together. Because I am an AWS Fanboy most of my designs and architectures revolve around AWS but some day I might actually learn another cloud and then utilize that instead. Fit for purpose.
Anyway, the markdown file will continually grow as I start to build the idea into a mostly detailed out document that lays out the architecture, design principals, technologies to utilize, user flow and much more. The more detail the better!
When I am satisfied with the initial idea markdown file I will provide it to Gemini. Its not my favorite AI model out there but it possess the ability to take in and track a large amount of context which is useful when presenting big ideas.
I assign Gemini the role of “Senior Technology Architect”. I assume the role of “stakeholder”. Gemini’s task is to review the idea that I have and either validate or, create the architecture for the idea. I prompt it to return back a markdown file that contains the technical architecture and technical details for the idea. At this point we reach our first “Human in the loop” point.
Because I don’t trust our AI overlords this is the first point at which I will fully review the document output by Gemini. I need to make sure that what the AI is putting out is valid, will work, and is using tools and technology that I am familiar with. If the output is proposing something that i’m unsure of I need to research or ask the AI to utilizing something else.
After I am satisfied with the architecture document I place that into the project directory. This is where we change AI Models. You see Gemini is good at big picture stuff but not so good at specifics (in my opinion). I take the architecture document and provide it to Claude (Opus, web browser or app) and give it the role of Senior Technology Engineer. Its job is to review the architecture diagram, find any weak points or things that are missing or, sometimes, things that just won’t work. Then build a report and an engineering plan. This plan details out SPECIFIC technologies, patterns and resources to use.
I usually repeat this process a few times and review each LLM’s output looking for things that might have been missed by either myself or the AI. Once I have them both in a place that I feel confident this is when I actually start building.
Because I lack trust in AI, I make my own repository in GitHub and setup the repository on my local machine. I do allow the AI the ability to commit and push code to the repository. Once the repository has been created I have Gemini CLI build out the application file structure. This could include:
- Creating folders
- Creating empty files
- Creating base logic
- Creating Terraform module structures
But NOTHING specific. Gemini, once again, is not good at detailed work. Maybe i’m using it wrong. Either way, I now have all of the basic structure. Think of Gemini as a Junior Engineer. It knows enough to be dangerous so it has many guardrails.
# SAMPLE PROMPT FOR GEMINI
You are a junior engineer working on your first project. Your current story is to review the architecture.md and the enginnering.md. Then, create a plan.md file that details out how you would go about creating the structure of this application. You should detail out every file that you think needs to be created as well as the folder structure. Inside of the architecture and engineering markdown files there is detail about how the application should be designed, coded, and architected. Essentially a pure runbook for our junior engineer.
Once Gemini has created its plan and I have reviewed it, I allow it write files into our project directory. These are mostly placeholder files. I will allow it to write some basic functions for coding and layout some Terraform files that are simple.
Once our junior engineer, Gemini, has completed I usually go through and review all of the files against the plan that it created. If anything is missing I will direct it to review the plan again and make any corrections. Once the code is at a place where I am happy with it, I create my first commit and push this baseline into the repository.
At this point its time for the heavy lifting. Time to put my expensive Anthropic subscription to use. Our “Senior Developer” Claude (Opus model) is let loose on the code base to build out all the logic. 9 times out of 10 I will allow it to make all the edits it wants and just let it go while I work on something else (watching YouTube).
# SAMPLE CLAUDE PROMPT
You are a senior developer. You are experienced in many application development patterns, AWS, Python and Terraform. You love programming and its all you ever want to do. Your story in this sprint is to first review the engineering.md, architecture.md and plan.md file. Then review the Junior Engineer's files in this project directory. Once you have a good grasp on the project write your own plan as developer-plan.md. Stop there and I, your manager, will review.After I review the plan I simply tell it to execute on the plan. Then I cringe as my usage starts to skyrocket.
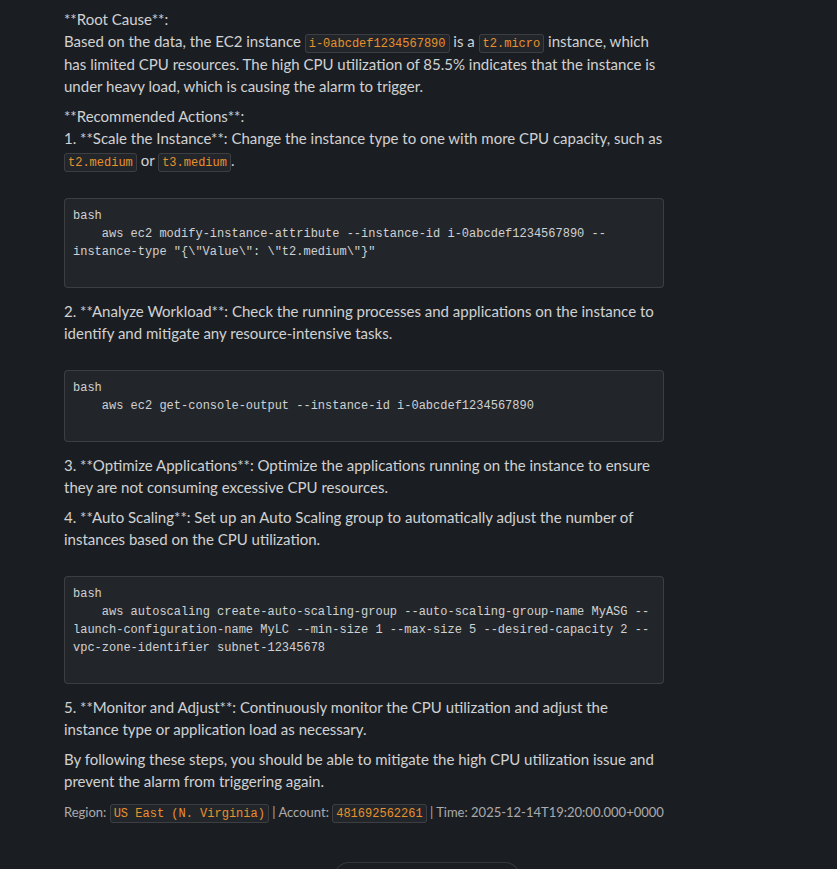
Claude will inevitably have an issue so I take a look at it every now and then, respond to questions if it has any or allow it to continue. Once it reaches a logical end I start reviewing its work. At this point it should have built me some form of the application that I can run locally. I’ll get this fired up and start poking around to make sure the application does what I want it to do.
At this point we can take a step back from utilizing AI and start documenting bugs. If I think this is going to be a long project this is where I will build out a new project in Todoist so that I can have a persistent place to take notes and track progress. This is essentially a rudimentary Jira instance where each “task” is a story. I separate them into Bugs, Features, In Progress, Testing.
My Claude Code utilizes the Todoist MCP so it can view/edit/complete tasks as needed. After I have documented as much as I can find I let Claude loose on fixing the bugs.
I think the real magic also comes with automation. Depending on the project I will allow Claude Code access to my Jenkins server via MCP. This allows Claude code to monitor and troubleshooting builds. This allows Claude to operate independently. What happens is that it will create new branches and push them into a development environment triggering an automated deployment. The development environment is simply my home lab. I don’t care if anything breaks there and it doesn’t really cost any money. If the build fails, Claude can review the logs and process a fix and start the CI/CD all over again.
Ultimately, I repeat the bug fix process until I get to my minimal viable product state and then deploy the application or project into whatever is deemed the production environment.
So, its 2026, we’re using AI to build stuff. What is your workflow? Still copying and pasting? Not using AI at all? AI is just a bubble? Feel free to comment below!