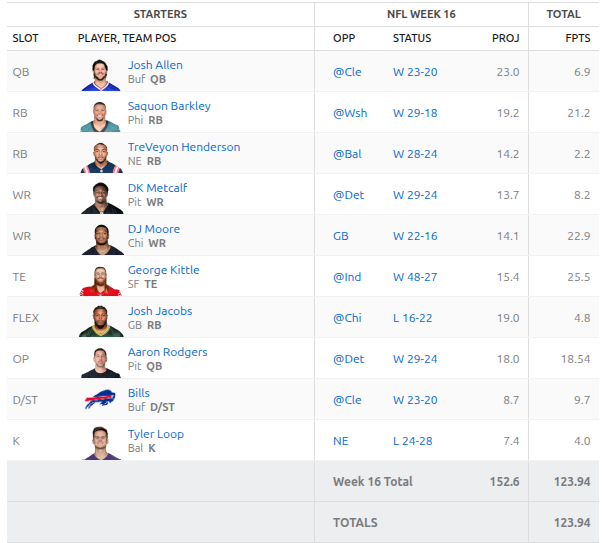
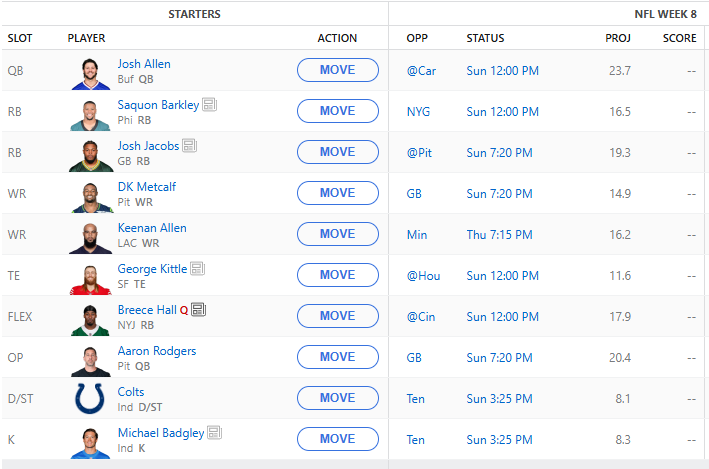
I think the AI mostly selected correctly this week. Unfortunately it wasn’t enough. We fell short by about 5 points. Going into Monday night we needed a massive game from George Kittle as the rest of the team performed very poorly. He delivered all the way until the 4th quarter where he likely twisted his ankle and was done for the game as the 49ers were up 2 scores.
Here are the results:
Josh Allen might have had a foot injury early in the game but stayed in for the entire game. The Bills simply didn’t throw the football. TreVeyon Henderson got absolutely demolished and left the game with a probable concussion. Josh Jacobs was questionable going into the game and cleared to play. The Packers simply didn’t play him.
With that loss we are eliminated from the playoffs and will be playing next week for 3rd place. Still a decent finish for our first year utilizing AI.
Looking Ahead
Through the off season I want to continue to work on the overall architecture of this agent and system. Ideally, I want to have the custom model built for next season and build an API around that to help us make better predictions.
Other action items:
Find a way to load news stories and story lines for determinations
Manage injuries/waivers better
Handle live NFL standings (teams eliminated from playoffs might play differently than teams fighting for a spot)
I also would love to be able to expose all of this publicly so that anyone reading can build their own applications around my predictions.
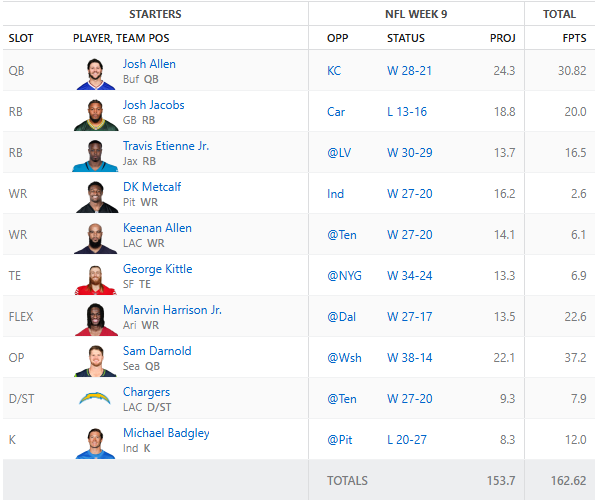
A BIG win in week 9! Our team is now tied for 1st place with 6 wins and 3 losses. We currently have 1318.66 total fantasy points on the season. It was looking pretty grim going into the afternoon games on Sunday. The receivers AI selected were not preforming and other players were barely hitting their projects. Josh Allen sparked some life into the team with his 30 points and then Sam Darnold showed everyone how to play quarter back with a 37.2 point performance! Check out the full results below.
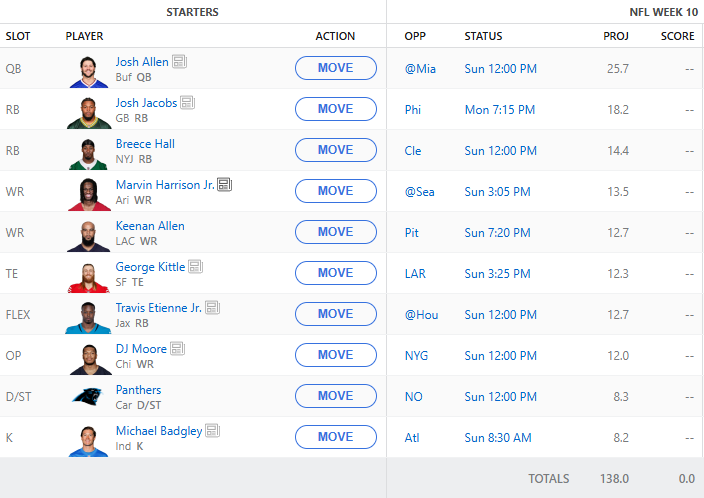
So, now we’re off to week 10. Currently, as I write this, Saquon Barkley is questionable to play. I would expect that he does play but the AI will not put him in the starting lineup. We picked up the Panther’s defense upon request from the AI. I would expect this is because they are playing the Saints who just traded away Rasheed Shaheed. The addition of DJ Moore into the OP slot is going to be a rough choice over playing a quarterback in that position. I’ll be monitoring the roster throughout the week to see if there are any other suggestions we can make. Here is what we are currently fielding into week 10:
Tune in next week for the results! Hopefully AI can get to 7-3!
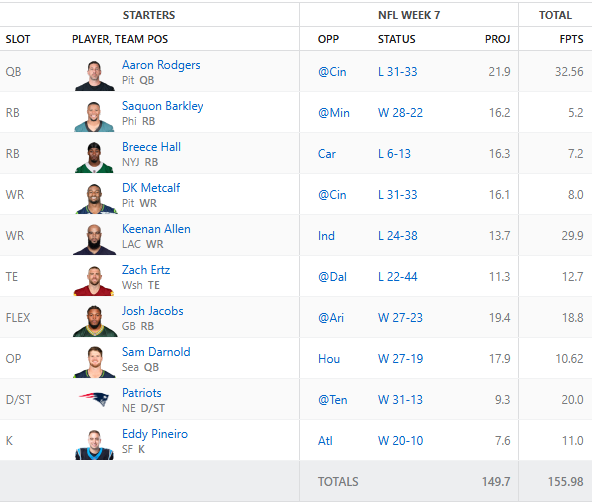
Well, our win streak was too good to be true. Unfortunately we lost a close one in week 6. It came down to the Monday night games and Sam Darnold just wasn’t able to get it going over the Texans even though the Seahawks still pulled out the win.
Our running back group also did not preform well outside of Josh Jacobs. The loss was by a difference of about 7 points so if anyone had put up another touchdown we could have won.
Anyway, on to week week 8. A few byes to contend with but otherwise most of are starts will be playing. The AI suggested grabbing the Colts defense and kicker as they are playing Tennessee. Breece Hall is currently questionable to play so we will have to keep an eye on that but he has a favorable matchup against the Bengals. The current roster is below.
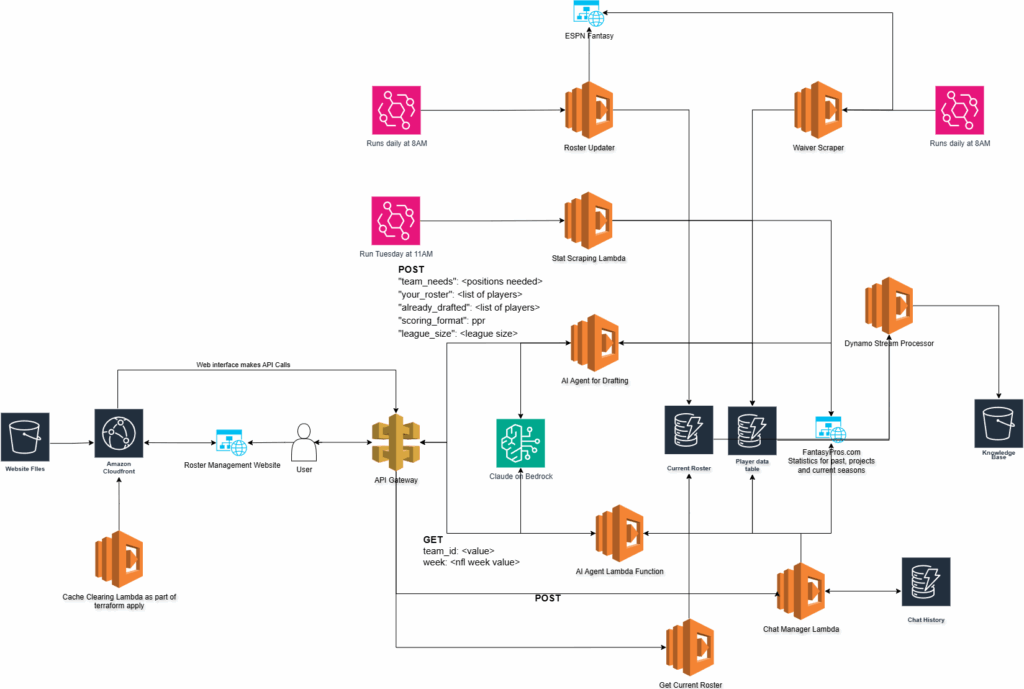
I promised to work on MCP this week but have only made a little bit of progress. I’ve been doing a lot of research on doing it in a cost effective manner as this project makes ZERO dollars and so I can’t afford to setup a bunch of expensive infrastructure. SO – this week I worked on combining the waiver table and the stats table into one table so that we can minimize DynamoDB calls throughout the application. The other thing I did was setup DynamoDB streams which are then converted into text files for each player and placed into an S3 bucket. This is what I think will be the first step in setting up a RAG pipeline so that a model can begin to be more “aware” of current NFL and Fantasy Football landscape.
Here is an updated architecture diagram. You’ll notice the S3 bucket on the right side. This is the eventual start of our knowledgebase.
You’ll also notice the waiver table removed. The new player structure looks like this:
{
"player_id": "George Kittle#TE",
"espn_player_id": 3040151,
"player_name": "George Kittle",
"position": "TE",
"seasons": {
"2024": {
"season_totals": {
"MISC_FL": 0,
"MISC_FPTS": 158.6,
"MISC_FPTS/G": 10.6,
"MISC_G": 15,
"MISC_ROST": "99.4%",
"Player": "George Kittle",
"Rank": 1,
"RECEIVING_20+": 21,
"RECEIVING_LG": 43,
"RECEIVING_REC": 78,
"RECEIVING_TD": 8,
"RECEIVING_TGT": 94,
"RECEIVING_Y/R": 14.2,
"RECEIVING_YDS": 1106,
"RUSHING_ATT": 0,
"RUSHING_TD": 0,
"RUSHING_YDS": 0
},
"weekly_stats": {
"1": {
"fantasy_points": 4,
"opponent": "NYJ"
},
"2": {
"fantasy_points": 13.6,
"opponent": "MIN"
},
"4": {
"fantasy_points": 10.5,
"opponent": "NE"
},
"5": {
"fantasy_points": 12.4,
"opponent": "ARI"
},
"6": {
"fantasy_points": 17.8,
"opponent": "SEA"
},
"7": {
"fantasy_points": 9.2,
"opponent": "KC"
},
"8": {
"fantasy_points": 18.8,
"opponent": "DAL"
},
"10": {
"fantasy_points": 11.7,
"opponent": "TB"
},
"12": {
"fantasy_points": 14.2,
"opponent": "GB"
},
"13": {
"fantasy_points": 0.7,
"opponent": "BUF"
},
"14": {
"fantasy_points": 15.1,
"opponent": "CHI"
},
"15": {
"fantasy_points": 6.1,
"opponent": "LA"
},
"16": {
"fantasy_points": 10.6,
"opponent": "MIA"
},
"17": {
"fantasy_points": 11.2,
"opponent": "DET"
},
"18": {
"fantasy_points": 2.7,
"opponent": "ARI"
}
}
},
"2025": {
"injury_status": "ACTIVE",
"jersey_number": "85",
"percent_owned": 98.97,
"pro_team_id": 25,
"season_projections": {
"MISC_FL": 0.5,
"MISC_FPTS": 147.6,
"RECEIVING_REC": 76,
"RECEIVING_TD": 7.5,
"RECEIVING_YDS": 1036.9
},
"team": "SF",
"weekly_outlooks": {
"1": "George Kittle is healthy and wealthy for the 49ers' Week 1 matchup against Seattle after signing a big four-year contract extension in the offseason. Kittle's role as a pass catcher should be intensified early on with WR Brandon Aiyuk (ACL) on the PUP list to begin the campaign and Jauan Jennings (calf, contract) uncertain to suit up against the Seahawks. Kittle is coming off a 78-catch, 1,106-yard, eight-TD 2024 campaign, further cementing his place as one of the NFL's elite producers at tight end. The Seahawks were middle-of-the-pack against the position last year, giving up an average of 51.5 receiving yards per game.",
"2": "George Kittle won't play in San Francisco's Week 2 matchup against New Orleans due to a hamstring injury that landed him on IR. Luke Farrell and Jake Tonges, who caught a TD in Kittle's absence last week against the Seahawks, will be asked to step in at tight end for the 49ers.",
"3": "George Kittle will miss his second straight game for the 49ers in Week 3 against the Cardinals while he remains on IR due to a hamstring injury. Jake Tonges and Luke Farrell should continue to hold down the fort at TE for Kittle until the latter is able to return. Kittle won't be eligible to suit up again until Week 6."
},
"weekly_projections": {
"5": 12.7,
"6": 13.1,
"7": 13.4,
"8": 11.7,
"10": 14.6,
"12": 11.6,
"13": 13.2,
"14": 13.4,
"15": 14.1,
"16": 14.1,
"17": 14.5
},
"weekly_stats": {
"1": {
"fantasy_points": 12.5,
"opponent": "SEA",
"team": "SF",
"updated_at": "2025-10-15T17:40:58.625370"
},
"2": {
"fantasy_points": 12.5,
"opponent": "NO",
"team": "SF",
"updated_at": "2025-09-16T17:08:05.179797"
},
"3": {
"fantasy_points": 12.5,
"opponent": "ARI",
"team": "SF",
"updated_at": "2025-09-23T15:00:13.907272"
},
"4": {
"fantasy_points": 12.5,
"opponent": "JAX",
"team": "SF",
"updated_at": "2025-09-30T15:00:14.035733"
},
"5": {
"fantasy_points": 12.5,
"opponent": "LAR",
"team": "SF",
"updated_at": "2025-10-07T15:00:13.665217"
},
"6": {
"fantasy_points": 12.5,
"opponent": "TB",
"team": "SF",
"updated_at": "2025-10-14T15:00:14.748804"
}
}
}
},
"updated_at": "2025-10-22T18:11:05.039158"
}
I hope to continue to refine this so that it can be used for future seasons. Then we can continue to use the bot into 2026’s season.
Anyway, hopefully I can figure out MCP and the knowledgebase this week. Winter is coming so its time to hunker down and build AWS Architectures!
The last you heard from me I was building a drafting agent for Fantasy Football. Well, the draft has finished and my roster is set. Behold, the Fantasy Football AI drafted team for my 8 team, PPR league.
STARTING LINEUP QB – Josh Allen (BUF) RB – Saquon Barkley (PHI) RB – Josh Jacobs (GB) WR – Terry McLaurin (WSH) WR – DJ Moore (CHI) TE – George Kittle (SF) FLEX – Breece Hall (NYJ) OP – Sam Darnold (SEA) D/ST – Lions (DET) K – Chase McLaughlin (TB) BENCH WR – DK Metcalf (PIT) WR – Marvin Harrison Jr. (ARI) TE – Evan Engram (DEN) RB – Aaron Jones Sr. (MIN) WR – Cooper Kupp (SEA) QB – J.J. McCarthy (MIN) WR – Keenan Allen (LAC) RB – Travis Etienne Jr. (JAX)
Now, I have also added another feature to the overall solution which is to include a week to week manager I’m calling the “coach”. I built a database that contains the 2024 statistics for each player and who they played against. I’m also scraping FantasyPros.com as well for future projections still.
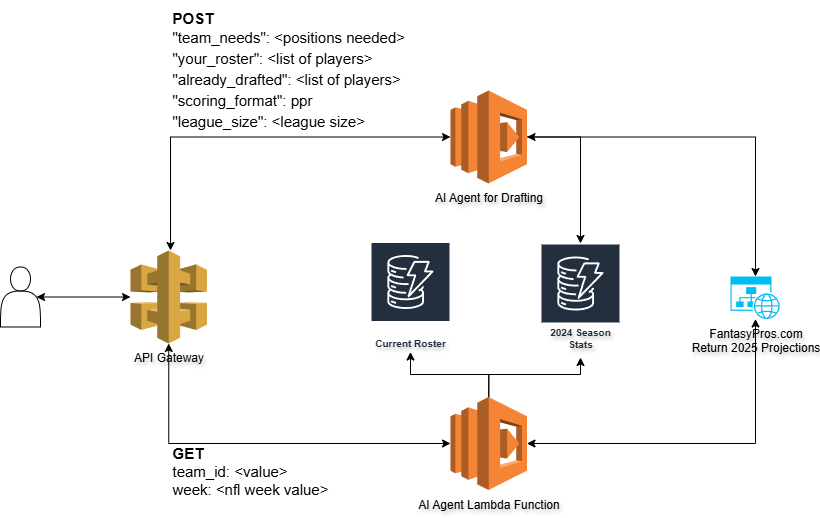
I added a new Lambda function and API call to my architecture so that I can send a request to the AI Agent to build out my ideal weekly roster.
The roster I posted above is what I will be starting for week 1. The agent also provides some context as to why it selected each player.
🏈 Fantasy Lineup for Team 1, Week 1
==================================================
🏆 STARTING LINEUP:
QB: Josh Allen (BUF) 23.4 pts
RB: Saquon Barkley (PHI) 19.9 pts
RB: Josh Jacobs (GB) 15.5 pts
WR: Terry McLaurin (WAS) 11.1 pts
WR: DJ Moore (CHI) 12.5 pts
TE: George Kittle (SF) 10.6 pts
FLEX: Breece Hall (NYJ) 11.5 pts
OP: Sam Darnold (SEA) 18.6 pts
K: Chase McLaughlin (TB) 8.5 pts
DST: Lions (DET) 9.2 pts
💯 TOTAL PROJECTED: 145.4 points
📋 BENCH (Top 5):
WR: Keenan Allen 7.6 pts
WR: DK Metcalf 8.6 pts
WR: Marvin Harrison Jr. 9.5 pts
WR: Cooper Kupp 9.0 pts
RB: Aaron Jones Sr. 12.8 pts
💡 COACH ANALYSIS:
==================================================
Made one key adjustment to the computed lineup: replaced
Keenan Allen with DJ Moore at WR2. While Allen showed
decent recent form (9.325 avg last 4 games), DJ Moore is
the higher-drafted talent with WR1 upside who should be
prioritized in Week 1. Moore's lack of 2024 data likely
indicates injury, but his talent level and role in
Chicago's offense make him the better play. The rest of
the lineup is solid: Allen/Darnold QB combo maximizes
ceiling, Barkley/Jacobs/Hall provide strong RB production,
McLaurin offers consistency at WR1, and Kittle remains a
reliable TE1. Lions DST should perform well at home, and
McLaughlin provides steady kicking in Tampa Bay's offense.
==================================================
There are still some gaps I need to fill with the data set as D.J. Moore did play in 2024 so I’m likely missing some data sets. I also have plans to build a “general manager” who can scan available players and find maybe some hidden gems on a week to week basis.
Finally, command line tools are fun but, I think the solution needs a web interface so watch for updates on that. The coach will inevitably automated and send me a report on the weeks performance as well as suggestions for the following week.
If you like Fantasy Football and technology follow along to see how this team performs throughout the season!
Last year I attempted to program a Fantasy Football draft assistant which took live data from ESPN’s Fantasy Platform. Boy was that a mistake…
First of all, shame on ESPN for not having an API for their Fantasy sports applications. The reverse engineered methods were not fast enough nor were they reliable. So, this year I took a new approach to building out a system for getting draft pick recommendations for my team.
I also wanted to put to use the example architecture and code I wrote the other day for the Strands SDK to work so I utilized it to build an API which would utilize the AWS Bedrock platform to analyze data and and ultimately return the best possible picks.
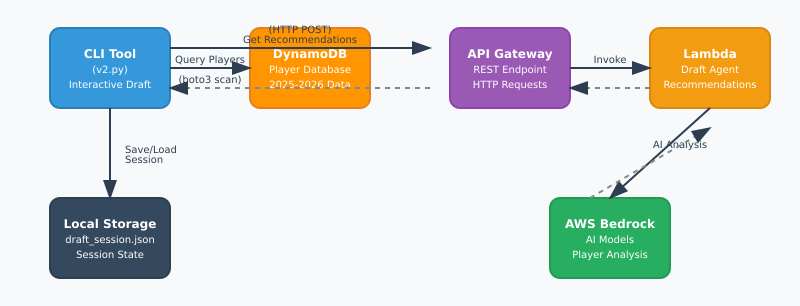
Here is a simple workflow of how the tool works:
I generated this with Claude AI. It is pretty OK.
The first problem I encountered was getting data. I needed two things: 1. Historical data for players 2. Projected fantasy data for the upcoming season
The historical data provides information about the players past season and the projections are for the upcoming season, obviously. The projections are useful because of any incoming rookies.
In the repository I link below I put a scripts to scrape FantasyPros for both the historical and projected data. It stores them in separate files in case you want to utilize them in a different way. There is also a script to combine them into one data source and ultimately load them into a DynamoDB table.
The most important piece of the puzzle was actually simulating the draft. I needed to create a program that would be able to track the other team’s draft picks as well as give me the suggestions and track my teams picks. This is the heart of the repository and I will be using it to get suggestions and track the draft for this coming season.
Through the application, when you issue the “next” command the application will send a request to the API with the current situation of the draft. The payload looks like this:
The “team_needs” key represents the current number of players remaining for each position. The “your_roster” position is all of the current players on my team. The other important key is “already_drafted”. This key sends all of the drafted players to the AI agent so it knows who NOT to recommend.
The application goes through all of the picks and you are able to manually enter each of the other teams picks until the draft is complete.
I’ll post an update after my draft on August 24th with the team I end up with! I still will probably lose in my league but this was fun to build. I hope to add in some sort of week-to-week management of my team as well as a trade analysis tool in the future. It would also be cool to add in some sort of analysis that could send updates to my Slack or Discord.
If you have other ideas message me on any platform you can find me on!
I have a PowerPoint party to go to soon. Yes you read that right. At this party everyone is required to present a short presentation about any topic they want. Last year I made a really cute presentation about a day in the life of my dog.
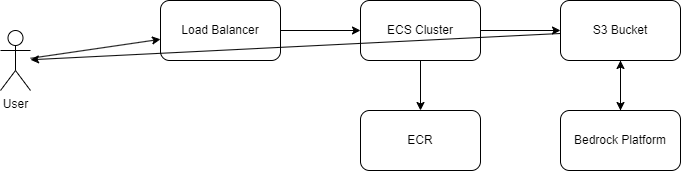
This year I have decided that I want to bore everyone to death and talk about technology, Python, Terraform and Artificial Intelligence. Specifically, I built an application that allows a user to upload an image and have it return to them a renamed file that is labeled based on the object or scene in the image.
The architecture is fairly simple. We have a user connecting to a load balancer which routes traffic to our containers. The containers connect Bedrock and S3 for image.
If you want to try it out the site is hosted at https://image-labeler.vansledright.com It will be up for some time, I haven’t decided how long I will host it for but at least through this weekend!
Here is the code that interacts with Bedrock and S3 to process the image:
def process_image():
if not request.is_json:
return jsonify({'error': 'Content-Type must be application/json'}), 400
data = request.json
file_key = data.get('fileKey')
if not file_key:
return jsonify({'error': 'fileKey is required'}), 400
try:
# Get the image from S3
response = s3.get_object(Bucket=app.config['S3_BUCKET_NAME'], Key=file_key)
image_data = response['Body'].read()
# Check if image is larger than 5MB
if len(image_data) > 5 * 1024 * 1024:
logger.info("File size to large. Compressing image")
image_data = compress_image(image_data)
# Convert image to base64
base64_image = base64.b64encode(image_data).decode('utf-8')
# Prepare prompt for Claude
prompt = """Please analyze the image and identify the main object or subject.
Respond with just the object name in lowercase, hyphenated format. For example: 'coca-cola-can' or 'golden-retriever'."""
# Call Bedrock with Claude
response = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": response['ContentType'],
"data": base64_image
}
}
]
}
]
})
)
response_body = json.loads(response['body'].read())
object_name = response_body['content'][0]['text'].strip()
logging.info(f"Object found is: {object_name}")
if not object_name:
return jsonify({'error': 'Could not identify object in image'}), 422
# Get file extension and create new filename
_, ext = os.path.splitext(unquote(file_key))
new_file_name = f"{object_name}{ext}"
new_file_key = f'processed/{new_file_name}'
# Copy object to new location
s3.copy_object(
Bucket=app.config['S3_BUCKET_NAME'],
CopySource={'Bucket': app.config['S3_BUCKET_NAME'], 'Key': file_key},
Key=new_file_key
)
# Generate download URL
download_url = s3.generate_presigned_url(
'get_object',
Params={
'Bucket': app.config['S3_BUCKET_NAME'],
'Key': new_file_key
},
ExpiresIn=3600
)
return jsonify({
'downloadUrl': download_url,
'newFileName': new_file_name
})
except json.JSONDecodeError as e:
logger.error(f"Error decoding Bedrock response: {str(e)}")
return jsonify({'error': 'Invalid response from AI service'}), 500
except Exception as e:
logger.error(f"Error processing image: {str(e)}")
return jsonify({'error': 'Error processing image'}), 500
If you think this project is interesting, feel free to share it with your friends or message me if you want all of the code!
Pre-signed URL’s are used for downloading objects from AWS S3 buckets. I’ve used them many times in the past for various reasons but this idea was a new one. A proof of concept for an API that would create the pre-signed URL and return it to the user.
This solution utilizes an API Gateway and an AWS Lambda function. The API Gateway takes two parameters “key” and “expiration”. Ultimately, you could add another parameter for “bucket” if you wanted the gateway to be able to get objects from multiple buckets.
I used Terraform to create the infrastructure and Python to program the Lambda.
The Terraform will also output a Postman collection JSON file so that you can immediately import it for testing. If this code and pattern is useful for you check it out on my GitHub below.
As many of you know, I released my Discord Bot Framework the other week. This has prompted me to put sometime into developing new features for the bot’s I manage.
I’ve always been a fan of the “remind” functionality that many Reddit communities have. In my Discord, we are often sending media content that I want to watch but don’t want to forget about. Hence the need for the command “!remind”. Surprisingly this was pretty simple code. Take a look below for the functionality I created.
@client.command(name='remind')
async def remind(ctx, duration: str):
try:
# Parse the duration (e.g., "10s" for 10 seconds, "5m" for 5 minutes, "1h" for 1 hour)
time_units = {'s': 1, 'm': 60, 'h': 3600}
time_value = int(duration[:-1])
time_unit = duration[-1]
if time_unit not in time_units:
await ctx.send("Invalid time format! Use s (seconds), m (minutes), or h (hours).")
return
delay = time_value * time_units[time_unit]
# Check if the command is a reply to another message
if ctx.message.reference and ctx.message.reference.resolved:
# Get the replied message
replied_message = ctx.message.reference.resolved
message_link = f"https://discord.com/channels/{ctx.guild.id}/{ctx.channel.id}/{replied_message.id}"
else:
await ctx.send("Please reply to a message you want to be reminded about.")
return
await ctx.send(f"Okay, I will remind you in {duration} to check out the message you referenced: {message_link}")
# Wait for the specified duration
await asyncio.sleep(delay)
# Send a reminder message with the link to the original message
await ctx.send(f"{ctx.author.mention}, it's time to check out your message! Here is the link: {message_link}")
except ValueError:
await ctx.send("Invalid time format! Use a number followed by s (seconds), m (minutes), or h (hours).")
Feel free to utilize this code and add it to your own Discord bot! As always, if this code is helpful please share it with your friends or on your own social media!
I’m happy to announce the release of my Discord Bot Framework. A tool that I’ve spent a considerable amount of time working on to help people build and deploy Discord Bots quickly within AWS.
Let me first start off by saying I’ve never released a product. I’ve run a service business and I’m a consultant but I’ve never been a product developer. This release marks my first codebase that I’ve packaged and put together for developers and hobbyists to utilize.
So let’s talk about what this framework does. First and foremost it is not a fully working bot. There are pre-requisites that you must accomplish. The framework holds some example code for commands and message context responses which should be enough to get any Python developer started on building their bot. The framework also includes all of the required Terraform to deploy the bot within AWS.
When you launch the Terraform it will build a Docker image for you and deploy that image to ECR as well as launch the container within AWS Fargate. All of this lives behind a load balancer so that you can scale your bot’s resources as needed although I haven’t seen a Discord bot ever require that many resources!
I plan on supporting this project personally and providing support via email for the time being for anyone who purchases the framework.
Roadmap: – GitHub Actions template for CI/CD – More Bot example code for commands – Bolt on packages for new functionality
I hope that this framework helps people get started on building bots for Discord. If you have any questions feel free to reach out to me at anytime!
Well, my AWS bill me a bit larger than normal this month due to testing this script. I thoroughly enjoy utilizing Generative AI to do work for me and I had some spare time to tackle this problem this week.
A client sent me a bunch of product images that were not named properly. All of the files were named something like “IMG_123.jpeg”. There was 63 total files so I decided rather than going through them one by one I would see if I could get one of Anthropic’s models to handle it for me and low and behold it was very successful!
I scripted out the workflow in Python and utilized AWS Bedrock’s platform to execute the interactions with the Claude 3 Haiku model. Take a look at the code below to see how this was executed.
if __name__ == "__main__":
print("Processing images")
files = os.listdir("photos")
print(len(files))
for file in files:
if file.endswith(".jpeg"):
print(f"Sending {file} to Bedrock")
with open(f"photos/{file}", "rb") as photo:
prompt = f"""
Looking at the image included, find and return the name of the product.
Rules:
1. Return only the product name that has been determined.
2. Do not include any other text in your response like "the product determined..."
"""
model_response = bedrock_actions.converse(
prompt,
image_format="jpeg",
encoded_image=photo.read(),
max_tokens="2000",
temperature=.01,
top_p=0.999
)
print(model_response['output'])
product_name = modify_product_name(model_response['output']['message']['content'][0]['text'])
photo.close()
if os.system(f"cp photos/{file} renamed_photos/{product_name}.jpeg") != 0:
print("failed to move file")
else:
os.system(f"mv photos/{file} finished/{file}")
sys.exit(0)
The code will loop through all the files in a folder called “photos” passing each one to Bedrock and getting a response. There was a lot of characters that were returned that would either break the script or that are just not needed so I also wrote a function to handle those.
Ultimately, the script will copy the photo to a file named after the product and then move the original file into a folder called “finished”.
I’ve uploaded the code to GitHub and you can utilize it however you want!